为什么我们说“悲观者永远正确,乐观者永远前行”?
因为除了持续的、坚持乐观继续前行,可能也没啥别的选择了
这里分享一个今天看到的小红书账号【椰果布丁少冰】
这个账号第一条帖子是23年12月29号发的
最开始发了40条,基本0赞、个位数赞。只有一条过10个赞
一直维持这种个位数的赞内容,发到了110条,也只有一条过了70赞
但,120条的时候,就有两条过70赞了、
130条的时候,多了一条700赞的、
140条的时候,多了一条3000赞的、
150条的时候,多了一条5000赞的
160条的时候,又多了一条6000赞的、一条2000赞的、3条400赞的
在这个过程中,这个账号调整了:主图的拍摄背景桌布、耳机壳的出镜个数、背景里放卡纸、背景里放书、手出镜/不出镜…
3个月时间,总共销量5000单,利润估计5w块
真是活该她赚钱
绝大多数人,都倒在了连续发布了100条(甚至都到不了10条)都没有正反馈的路上🫠
(img)
以“AI对话抓取数据下载为Excel文件”为例,给不懂开发的人解释下这种一句话需求,程序员去实现,要几步。
注意,并不是你调用个GPT接口就能够拿到 Excel 文件的。
我们以 Python 为例,具体需要以下几步:
准备好一个对话框;
基于用户在对话框里的需求,调用GPT接口分析需求,生成谷歌搜索查询语句;
调用谷歌搜索接口,根据语句拿到网址列表;
基于网址列表,用 Python 爬虫库一个一个网址去爬网页,获取网页 html 代码;
把爬到的html代码做一些简单的过滤后,提交给GPT提取数据;
让 GPT 把所有提取的数据汇总,生成文本格式,如 json 格式;
去 Github 找一个 Python 的 Excel 库,用 Python 把 json 格式数据转成 Excel 库所需格式,调用库,生成 Excel 文件;
把 Excel 文件下载地址返回给用户
澳大利亚临终关怀中心有一位护士,专门照顾那些即将去世的病人,通过记录和病人的对话,她总结出了人临终前最后悔的5件事。我希望我有勇气过忠实自己的人生,而不是别人期望我过的人生。
我希望我以前没那么拼命工作
我希望我有足够的勇气表达我的感受
我希望我能够和我的朋友们一直保持联系
我希望我已经让自己更快乐一些
白手起家:
如何完成
资本原始积累
轻资产:
时间投入代替资产投
入” (Time in Money Out)
“收付账款套利行为”
(Money in Money Out)
(先收钱,再付钱)
杠杆效应:
核心:借势+网络
借势:拿下最有议价权的环节
或人
网络:互联网的低成本杠杆效
应,本质是“做势”,不借他
人,打造和包装自己。
白手起家的关键在于速度,用
最少的时间迅速撬动最多的资源,每个时间段都不可逆
可复制:
核心:投入复利性
“规模可复制”+“经验可复制”
关键:选择的收入流市场足够
大,可容新进入者(新入者和
存量者的差异井不大)
切记,在有鱼的地方打鱼。
上下游可延展:
核心:“赚人”
如果可延展,那么你可以不赚
钱,而是用来赚(势/人),以
时间换空间。
我最早选择行业就具备此特
点,因此第一阶段我选择用来
赚人。
第二阶段后,所有人都会成为你的收入流。
适合宝妈的副业,JOJO生日视频(25)
简单说一下数据,观察了2个号,分别是几百粉、几千粉,每天发的内容就是 JOJO生日祝福视频。
点赞都差不多,几十个,评论区都是宝妈在求视频。
-
视频内容一般就是JOJO的一段动画,会出现你的小孩子名字和照片,然后一些祝福的话,比较喜庆。
这种视频一般是用在生日宴会上,作为预热节目在电视上播放。
-
内容创作的话,我觉得挺简单的,内容都差不多,应该是套的模板。
除了JOJO,还可以拓展到其他小孩子喜欢的动画人物,比如奥特曼、冰雪女王啥的。
-
要想走高端路线的话,我觉得可以用AI定制个人形象,比如在视频中加入孩子的AI艺术照。
家长肯定都望子成龙嘛,加入AI学士服照片,或者AI领奖照之类的,寓意美好未来。价格就可以拉高点。
而且生日宴会这种场景,肯定每年都要的吧……
-
变现方式……除了定制视频,还可以教学嘛。
-
感谢阅读,我是写代码的安徒生,这是我第25篇副业观察。
服务富婆和中年拆迁户,能赚大钱。
如题,继续写我们群响高客单价私欲 IP 班的案例,
高客单价领域,真的太大了,太适合草根创业者了。
昨天案例研讨会的 6 个高客单价的精彩操盘手分享,分别服务留学、珠宝、餐饮老板、移民、夫妻老婆店老板、房地产老板,
值得学习。
一、
留学保录取 + 留学规划,
只服务 50 万支付能力的客户,只做英国和美国的本科客户,只做珠三角领域的超级有钱客户,
上门服务、转介绍驱动、不做任何公域流量,3 个人,体量 500 万,比较小。
现在焦虑的点是要不要扩张,我说你是疯批吧,这个赛道偷摸赚钱,扩张你等着被锤死嘛?
二、餐饮老板培训。
3 个人,300 万,只做一门课,餐饮老板差异化定位,就是一个讲师。
不会做流量,只弄转介绍,居然开课开了好多年,这让我很吃惊。
她说很多知名品牌在知名前都来上过她的课,差异化是必学模块,她是这一块比较牛逼的老师。
目前的问题是如何搞流量。
我跟她说看您这个面相,不太适合自己搞,但是代运营又会被割韭菜。
我提供两个思路,
一个是寻找联营方,认真耐心地寻找一个,但要看缘分。
一个是自己像群响一样,就是疯狂搞线下活动,其他啥都别看。
自己在流量上很差就放弃这个赛道,餐饮老板一定是一直有信息培训需求的群体,
锁定他们,持续做转介绍私欲吧。
三、
移民,主要做 to B 转介绍,做美国、澳大利亚、加拿大、新西兰等五眼联盟的身份,
不做公域,客单价 10 - 50 万左右,服务都是谨小慎微的中国土老板,
她说,很难突破流量维度,但是感觉这个生意是一个大生意。
我说卧槽这个生意,比前两个还更不能 to C,to C 必然被锤,
任何 short China 的人都将收到惩罚,你自己要移民自己做啊,何必做 IP,你要学习如何经营朋友圈。
不要再 lowlow 的发什么审批通过的 Offer 截图了,low 死了。
四、
房地产炒房团服务,一个公众号爸爸,最大的房地产专业投资公众号团队的 CEO,
一方面粉丝是富婆、土老板、拆迁户,这些人有 800 万可杠杆现金,
中国人主打一个富贵险中求,所以就在他们的带领下,干房地产投资,
一方面是创始人认识房地产公司,原先赚了很多服务费和 CPS。
两边撬,但是经济下行期,如何正确做这个生意呢?
我说,大姐这个时候狗着比较好,一定要正能量,一定要防火防盗防封号,
然后海外肯定是重点,因为最重要的是这群炒房客对你们的信任。
哪怕今年生意不做,也需要把新业务的信任弄起来,而不是强行夸夸,然后忽悠客户。
一旦有 badcase 就很难。
五、
珠宝 A 货,3000 个私欲,一年 500 万,4 个人,老板是 IP,也是供应链负责人,也是客户直接负责人,其他都是定制师。
这真的是一个大买卖,好好做啊,这么少的客户群体!!!
老板娘是一个温润如玉的人,看起来就是卡地亚的标准客户,但是她说,
他们和卡地亚是绝对竞争对手,而且大部分买他们的,都是图便宜。
珠宝 A 货,提供以假乱真的服务,全是真的珠宝,货真价实,同款打造,
但是没有品牌,便宜 90%,所以说她的客户有几种,
一种是金领女性自我取悦,一种是富婆相互送礼,一种是老公送老婆,
全靠转介绍,真是开了眼。
关键是珠宝 A 货不丢人,因为珠宝是真的呀!!
我跟她说,老板娘你别焦虑,就好好发朋友圈,该要你的人,会找到你的。
六、
夫妻老婆店培训。
郑州一家公司,10 个人,2000 万,老板做 IP,5 个私欲客服,
只服务汽修店土老板,这些土老板需要在抖音搞流量,但是他们不会。
这个老板也是汽修店出身,所以懂得如何对话,如何教他们,
9800 元一年 VIP,教练学,让你学会如何在抖音搞汽修店的流量。
除了这个之外,还卖一些供应链上下游的产品。
老板来学习如何精细化朋友圈运营,看起来悠哉悠哉,因为他碰的是他最能对话的群体!!!!
草根出身的夫妻老婆店小老板如何做抖音,够接地气吧!
七、
给我的启发是什么。
第一,细分垂直,细分垂直,细分垂直,这是王道!!!!垂,才能隐,才能偷摸赚钱。
第二,IP + 私欲 + 高客单价,是今天国内的主流模型,请务必记住,这是所有公司都会走上的路,利润驱动。
第三,服务,而不是洗,通过服务建立信任,然后成交,不是洗流量,因为你没有那么流量。
第四、锁定高质量客户,其实没有流量,也不会死,只是焦虑,锁定!
我发现我们开凿了一个金矿人群 —— 中国高客单价 IP 私欲操盘手,
中国创业者,大有希望,而强者,从来不抱怨环境。
若你是这样的人,私信我哈。
和户外品牌“骆驼”的总裁万叔一起游学了几天,从前辈那儿听到了很多引发思考的观点,记录下来:
1⃣️落一个新项目,要落就落在最贵的地方。来洛杉矶考察了一圈TikTok生态,这边的成本真不便宜,如果落在美国其他州,成本可以低很多。
万叔的建议是,要落就落在最贵的地方,这个地方贵有贵的原因,比如基础设施、生态更好。起一个新项目的时候,未知的坑还有很多,没有必要在这时候为了省一点成本,就给自己制造更多的障碍,增加试错时间。在选址时候省下来的钱,会在后面因为省钱而踩的坑里都还回去。
2⃣️保留创新和竞争的气口。在公司测试新渠道(比如天猫、抖音)时,他会在公司内搭两个赛马团队,同时在外面请代运营团队。
这样做可以通过不同团队的结果反馈进行交叉验证,对新渠道有更全面和深刻的认知,也能促进团队的活力。
另外,公司也会保留一些经销渠道,目的不是为了挣钱,而是通过这些经销商留意市场上出现的新的玩法,与时俱进。
3⃣️找好对标,深耕行业,想清楚自己的创业节奏。创业初期可能没有很多的资本做支撑,那么就快速跑通链路,等起量之后把自己的业务做重(比如深耕供应链、比如打造自己的品牌),形成自己的竞争壁垒。
在这个过程中,找好自己的对标,并且深耕自己的行业。万叔对自己行业内的竞品及其发展路径、具体数据如数家珍,在持续关注竞品的过程中形成自己的迭代和进化思路。
4⃣️产品为王,对新渠道保持敏感。聊到骆驼品牌三次重要的大增长时,万叔提到,第一次是从鞋子转型做户外服饰,第二次是从卖场渠道转铺商场渠道,第三次是重视电商新渠道的拓展。
三次大增长中,第一次是产品方向确立,第二、三次是新渠道的敏锐关注+选择。这次和我们一起来美国考察TikTok,也是因为他看好这个新渠道带来的潜在增长可能性。
万叔提到,产品是核心,渠道和供应链都是笨功夫。但这些笨功夫,花心思打磨后是极强的壁垒。
最后,创业也好人生也好,结果、财富不重要,享受过程。
圆桌:对话奇绩创坛合伙人——探索创业之路的守正出奇
出席:毛圣博Peter、李晨啸race、林沅霖、徐律涛
YC 创立:Paul 05 年创立 YC,YC 在哈佛大学举办第一期夏令营,Sam 是当时的第一期。
模式:CoFounder as a service,创始人为先,先投资后加速,没有对赌。每年投资超过 100 多个项目,覆盖 20 多个前沿科技领域,喜欢投怪的项目。核心解决 PMF 问题。每周与合伙人一起解决问题 Office Hour 和 Group Office Hour。大咖闭门分享。路演日,面对上千个投资人。Bootcamp,针对早期创业的核心问题组织专题学习。产品日,帮助入营项目对接产业链上核心生态企业。
第一场
王ZY:19级信电,目前在华为。曾经在阿里云做 OAM 实习。想法:大模型需要很高的算力资源,希望做边缘计算,面向机器人的 AI 云上推理服务平台。主要问题:需求是否是真实的?如何找 CoFounder?
毛:很多人会拿着锤子找钉子,需要立刻去找用户聊,最好现场让用户看着开发,问卷需要但往往不真实而且水平比较低,做 AB 测试,扩大调研范围。可能大型企业不需要,看中型企业或者小型企业。toC最好有 demo 看用户是否点了那个button,混进竞争对手的用户群看用的最多的功能和最不爽的功能,做 10 倍提升。还可以调研上市公司,大公司其实是软柿子,因为他们调头比较麻烦。
Race:我们做 toC,共创社区。我的方法不是很通用性,自己是一个创作者。当时做 StepBeats,下载百万级,苹果编辑推荐,当时用户留存比较难,发现自己共情能力比较强但服务用户的意愿不强,发现创业是加杠杆,宁可不创业也想做,从自己的兴趣爱好出发,自己是自己的产品的用户。
沅霖:站到客户旁边,用户不需要服务器而是需要能让自己的产品发布上线,所以做了 pass。我们找到的用户可能是幸存者偏差,不是更广大用户的代表,即使自己是自己产品的用户。我们可能不需要扩大垂直服务的领域,不需要满足全部用户的需求,我们需要定义我们的用户范围。用户画像定义清楚后,假设自己产品已经完成了,看之后的增长能否找到稳定的获客渠道。
毛:还是和用户聊的太少,然后需要确定好用户范围,然后可复制性(PMF,YC认为PMF非常难,需要1-4年,其实做到PMF就能上市)
LT:解决LLM可用到可商用的最后一步。黄铮说:做正确的事情,把正确的事情做对(?)。Qi,人总是会变的。我们要找到自己的价值观,然后看这个价值观能否和做的事情兴趣匹配,不需要直接找一件事。可复制性用笨办法,保持平常心,每周找10个用户。找到一个事情作为起点,不要抱很大的执念,然后用笨办法慢慢找客户。
毛:People Mission Fit,不是自己的喜欢的事情很难坚持。大学生第一个想法靠谱概率很低,但是可能副产品可能就跑出来了。很多项目都是撞出来的,但是需要在路上,很多公司 Pivot 非常多次。旷视第一天做游戏,后来是一家安防公司。Insta360 一开始做在线直播,后面做运动相机。
毛:第二个问题怎么找 CoFounder。成功率最高的 CoFounder 就是学校同学。负担小,机会成本很低,失败对于再创业或者打工都很有用。首先要了解自己,我的长板和短板,核心团队需要有乐观的人和悲观的人,Founder 人数 2-3 比较好,因为很多人会跟不上。股份不能平分,人数最好不多于 4 人,找和自己互补的人,把自己的长板发挥到极限。
LT:打互联网+认识race。信任关系的构建很困难,大学是一个比较好的地方,有信任基础;广撒网,在各个平台发JD,最后找到的还是浙大的,没有捷径;找任何人不需要把他作为一辈子创业伙伴,要很好直率地表达分歧
YL:找 CoFounder 比较单纯,在外包开发认识。找 CoFounder 很放心,足够了解,愿意能放弃其他选择来参与,不需要找一个技术特别强的,而是要找一个信任的、能坚持的,退路不多,不喜欢打工不想当公务员抗压能力很强,或者找不到工作职业技能找不到匹配的
Race:也一直在探索,没有 BestPractice。自己要对自己有 100% 的信任和坦诚,然后找 CoFounder 也要找能对自己 100% 的信任和坦诚。
毛:找自己喜欢的,相处舒服
第二场
X:这一届进入奇绩,刚天使投融资完,便携的智能望远镜。研三,半辍学。加个几百个投资人,我们怎么对投资人做梳理和分类,如何巧妙地维持长期的关系。
毛:这个阶段投的是人,和投资人聊的是这件事能做大,提高可信度,对这个事情有多久多深的思考,有没有 insight 洞察。比如为什么不做一对一,最好的老师宁愿做一对多,一对一关键不是课讲的多好而是陪做作业(好的不需要讲差的讲不了,关键是中间的人的提高,而中间的人其实是自制力不强)。故事有insight,和人匹配,有可信度。梳理可以用database,比如企名片,看是否活跃。不可能所有投资人都喜欢你,但只需要有一个人愿意投你就可以。第一印象比较重要,然后看为什么不愿意投。如果是觉得金额比较高,那可以和他们说分两笔,然后定个milestone再发第二笔。如果是缀学我们会非常重视,说明决心非常强。
Race:我和投资人很坦诚。我是一个艺术家,我相信商业和科技是艺术接下来的必要,做到了 People Mission Fit。
YL:不用排斥找 FA。Founder 可能觉得我们对自己的产品最懂,但是 FA 是最了解 VC 的,他们掌握的信息更多,他们会帮你先补齐漏洞
LT:坚持自己的想法很关键。黄铮认为,创业也有小学中学大学。坚持找到能认可自己想法的人,“等你有进展”其实就是婉拒
毛:很多大的公司早期融资很困难,很多 VC 看好的做不大。当大多数人觉得不行但最终证明是对的事业(小概率)能做到非常大,比如拼多多。第一性原理。心要大。奇绩报名表:你有没有什么不同的idea别人很不同意但你很坚持
Q&A
做跨境电商,比如东南亚最近的情况非常危(印尼封禁 TikTok),想问下这个赛道
大走势是:供应链转到东南亚,会导致东南亚发展变快,最好是实地跑一趟,待个几周的时间。没有调研没有发言权现在做复刻数字人,目前刚拿到天使,这个市场怎么看?
很多公司融的越好就容易挂,扩张可能过快,心态比较膨胀。数字人是一个很大的机会,toC 陪伴,比如 minimax 的星野(?)。需要回归第一性原理,找到核心需求,愿不愿意付费,愿不愿意长期付费,比如旅游很低频,不要做低频生意,携程主打商务。做偶像虚拟人,需要多找年轻人找 CoFounder 问题,没有找到特别好的idea的时候怎么找人,或者说idea和人的优先级
事和人可遇不可求,找到人没有idea可能先尝试做一些项目,先上牌桌,考察合伙人,骑驴找马。有好的idea更容易找人,说服人需要有故事,三套故事:投资人、员工和客户
race:我是想清楚再找人,但也可以找人一起想;YL:还是先找事情,但是找事情的最好的方法可能是找人,去看这个人在这个领域有没有需求;LT:想办法站到更高的地方去,比如找牛逼的人聊,提高自己的认知,不要脸,Qi特别讨厌觉得自己牛逼的人,其实牛逼的人很谦虚,可以找他们去聊他们很多会愿意。如果找人找事都没有可能得站到更高的地方去
观众:刚毕业的人认知极浅,建议找个领域扎进去
毛:不需要进入特别卷或者特别需要经验的领域,去找经验可能成为包袱的领域,比如大模型、社交,开发对年轻人有用的东西,toC,但是如果需要很深人脉、很深技术、很多资历(芯片)的领域不要做。年轻人做电商都不太适合。核心就是 make something people want,我们要 think differently,不要太乖,学习最好去当教授了
用户输入需求,输入场景和面临的问题
推荐商品
生活上也好
大件上也好
做成硬件设备免费送到家里
语音输入,生成商品
收广告费
先只要品类品名回复(买关键词热度、商家seo优化)
积累用户
然后推荐平台甄选
翻译软件词典工具截屏翻译
ocr
截屏功能足够好用,贴图、历史剪贴板
快速了解一个行业
第一部分,如何快速进入一个新领域:
一、准备工作
前提是你要对这个新领域建立框架,对,就是
结构!
有了这个新领域的知识结构,你学东西起来,
会又快又顺,因为你知道你现在学的东西,在
结构里的哪部分。
知识结构就好比一棵树,你要先把树干种下
去,等它长出枝丫,这时候这个领域的知识结
构就被你搭出来了,否则一开始你只是在捡树
叶(一些零碎知识),收集了一堆,要用的时
候,不知道从哪里找,一团糟,而且一旦有什
么客观外力,比如风来了,你这些树叶就随风
散落去……前面花的时间和精力,前功尽
弃.…
10486
那问题来了,如何搭建一个新领域的知识结
构?
如何搭建一个新领域的知识结构
1、踩在巨人的肩膀上
因为咱们是学东西,而不是发明东西,所以要
学会“借鉴”,也就是踩在巨人的肩膀上,比
如你可以参考:
1)这个领域的教科书/专业著作,其中的大纲
就是知识结构
2)找专业的信息源或这个领域牛人发布的文
献和文章,比如我经常会找一些文章,标题一
般是《一文读懂…》《一篇说透…》《史
上最全….》
这些文章,我通常会看3遍以上,但第1遍我会
看的非常快,这些文章包含了什么小标题,这
些小标题基本就是这个领域的知识结构,里面
的细节和信息不用过渡在意,后面等入门了,
再慢慢看这些内容都来得及。
举个例子,我之前在学小红书的时候,“踩在
巨人的肩膀上”,这个巨人就是小红书的官
网,我明白:
做小红书的主体,主要是个人和品牌两类,但
想做好都是要做好人群和内容的匹配(即符合
小红书平台算法),于是我给自己列了一个
“一周学习计划”
1) 理解小红书算法
2) 爆文逻辑,图+文设计、排版和搭配
3)运营方式
4) 变现方式和后端承接
5)投放方式
6) 查漏补缺日
7)查漏补缺日
然后……就被公司赶鸭子上架去做项目了,然
而也没有垮掉!甲方爸爸很满意!
2、不断问自己“为什么,然后呢”?
这对于应对一类现实问题是十分有效的,在过
程中,你不仅解决了问题,还能建立处理这类
问题的基本框架。
比如,运营人最常遇到的问题就是:
这个月我要如何完成增长目标(GMV)?我
每个月都会面临这个问题,我就会不断问自己
“为什么,然后呢”?
GMV由什么构成?
提升GMV,就是让更多人来买更多次,这里
包括新客和老客,然后呢?
GMV由什么构成?
提升GMV,就是让更多人来买更多次,这里
包括新客和老客,然后呢?
再进一步拆分,让更多人来买多次,包括:
同一个人多次购买、同一个人每次买更多、同
一个人推荐更多人来买。
其中的关键要素包括:流量、转化率、复购
率、客单价、裂变率和连带SKU销售率,详细
可看图。
3、依靠流程路线去梳理
同理,这对于应对一类现实问题是十分有效
的,在过程中,你不仅解决了问题,还能建立
处理这类问题的基本框架。
之前我转岗课程产品经理,一门课程如何从诞
生到上架卖爆,我是一头雾水,其中我要掌握
什么知识嘞?我就按照“一门课程如何从诞生
到上架卖爆〞这条流程路线进行了梳理,包
括:
- 选题确定,找老师
2)老师同步课程定位、目标人群和基本目标 - 第一次课纲共创会
4)形成MVP小课,放在线下做试课会
5)第一次课程逐字稿+PPT初稿 - 内部课程产品组评审
- 邀请MVP小课用户上线反馈
8)老师根据内外部意见反馈迭代课程同步上
线课程售卖页同步 与班主任共创打爆前3团运
营计划
9)制作课程售卖弹药包
10)准备课程交付文件包
11)线下课程进入交付
按照流程路线图走,这就是我由增长运营转岗
到课程产品经理的行动规划,很清晰,而且
打磨课程中还借力了我的运营技能,很快实现
了成功转岗。
补充一下,行业的insight你可以从下面渠道获
得(社区团购相关的行研上面很多,每周日我
的报告阅读来源90%也来自以下):
镝数聚(覆盖100+行业报告及数据,更新及 (058512188
时,支持报告与数据交叉查询,80%可以免费
下载)dydata.io/
艾瑞网(互联网行业报告、APP日活月活查
询)report.iresearch.cn/
199IT(报告集合引擎)199it.com/
A486
CNNIC(互联网发展研究报告)wxzbg/
Talking Data(互联网研究报告)
category=IndustryReport
rts.html?
艾媒网(互联网研究报告) iimedia.cn/
梅花网 (营销信息、咨讯) meihua.info/
极光(研究报告) jiguang.cn/reports
:512188
企鹅智库(互联网研究报告) re.qq.com/
普华永道(行业研究报告) pwccn.com/
zh.html
BER512188
QuestMobile (行业研究报告) arch/
report-new
麦肯锡(洞见和麦肯锡季刊板块)
482888587
mckinsey.com.cn/
罗兰贝格(行业研究报告)
rolandberger.com/zh/?
48288858512188
埃森哲(行业研究报告) -applied-now
##ishot提示需重新下载
打开包内容
Contents/Library/LoginItems
删除iShotProHelper
1,富人最大的财富,不是豪车,豪宅,不是乱七八糟的文物,存款,富人最大的财富,是穷人。
2,动上层的利益如同夺他们的生命。改底层的观念如同掘他们的祖坟。因为底层观念正是上层利益的来源。
3,这个世界是虚构的。
国家、宗教、社会制度、法律,都是人类想象出来的东西。
上等人用想象出来的东西把人分成了三六九等,不同阶层的人看到虚构出来的不同的世界。(这段话是参考人类简史写的 非常经典的一本书)
4,怎样才能赚更多的钱,国家和老师已告诉我们答案。
答案无非是天道酬勤,勤劳致富
这些答案,真的能改变N多兄台的命运吗?
我不知道,我只知道,真正掌握潜规则的人们,他们会制造出大量有组织有杀伤力的信息对底层的普通人进行洗脑,让我们相信按照某种策略与战术,就能让我们赢得一切。前提也就是简单,听话,执行,遵守他们制定的规则与章程。
真正赚钱的秘密,从来都没有兄台会在大众生活中热烈讨论,而是深埋在塔基之下。
真正获取财富秘密的人,哪怕他是我们最好的朋友,他们也不会告诉我们他们内心最真实的想法!
就像我们县,有个兄台发家致富就是靠偷车卖车积累了第一桶金,现在你问他:“怎么赚那么多钱?”他会笑呵呵告诉你:“都是打工攒的,现在开了个旅店,稍微赚了点钱。”
我买的新冠保险,说确诊了给赔5万
后来全国都阳了,打电话就说不赔,说合同上写的是新冠病毒肺炎,我不是,我没有肺炎,最多把买保险的钱退给我
我问了家人,还有同样买了保险的网友,他们都说算了,斗不过的,人家法务团队老牛逼了,我连法院门儿都不知道长啥样
我就不服,应该给我的东西凭啥算了
大冬天线下去找银保监举报,还以为管用,以为国家部门能主持正义,毕竟网上都这么说
举报完保险公司打电话说赔200,我就呵呵,银保监会也就值这200块钱了
保险公司还说就这些了,有本事你就走诉讼
说的好啊,过完年回来我直接找人起诉,材料邮寄上海,那边法院材料刚签收,我还没有收到法院交费通知短信呢,保险公司就打电话过来了
张口就是两万,说走诉讼有办法拖我几年,我说你有本事你就拖,反正我只要交费了就打到底,一审不行二审嘛,就算打输了我也要给你套上一层魂环
客服说会向上汇报
第二天上午给开到4万,我说该多少就多少
下午给5万,但是要签署保密协议,我
签个屁
我说不可能签,不接受任何条件,全款理赔,你还有条件咱们就走诉讼吧,没错,这次这句话是我对他们说的
第三天客服就同意了,全款理赔,没有任何其他条件
我跟我对象,两个人都买了,一共十万到手,这钱就是这么争取来的
跟我一样买了保险的,有的人直接自己认为那么多人阳了,肯定不赔,连给保险公司打电话都没有
有的人问了保险公司,人家说不赔,就放弃了
有的人争取一下,想靠政府部门,结果拿了一点儿甜头也萎了
所以说世界的真相是什么?
是你不争,该是你的照样不给你
你以为不可能的事情,就是有人争取到最后,有人拿了全款,有人山穷水尽,但也有一瞬间的光照到你我
靠人人走,靠山山倒
以斗争求和平,则和平存
以妥协求和平,则和平亡
诸位共勉
产品总监告诉我信息流广告和营销短信的退订目的不是减少打扰用户,而是告诉系统这个用户是活跃的,从而给这类高价值用户推更多广告获得转化。以前我还觉得他这是黑暗的想法,互联网没这么龌龊。没想到最近淘宝首页不知咋的给我推了个壮阳药,我点不感兴趣结果首页壮阳药广告更多了,最后赶紧搜了很多数码产品壮阳药广告才消失。
微信订阅号消息也遇到同样的问题,天天推女明显穿性感衣服差点漏点,但目前没有办法能把这些乱七八糟的推送取消掉。
中国人均每月可支配收入在5,000块钱以上的人只有7200万,在2000块钱以下的有9.6亿人
这就是在中国做消费的基本格局,这个帐算不清楚,就不应该创业
#内幕消息
探访假牙源头工厂获取的业内信息差:
口腔医院密不外传的看牙省钱指南
绝大多数人牙齿修补的流程是直接去口腔医院或者诊所,医生提供诊疗方案,消费者掏钱。然后牙医取模型提交工厂把假牙制作出来,医生给消费者安装上。
价格构成:
-牙医诊疗和安装费
-牙齿工厂制作费
-牙医加到牙齿上的抽成。
导致两个问题:
1.牙齿出厂价对于消费者来说是不透明的,所以中间的抽成往往成为牙医的利润空间,因此看牙贵以及市场价格差巨大。
2.因为缺乏足够的业内信息,所以盲选牙医,容易碰到不靠谱的。
一个更省钱且省心的方法是:通过工厂对接医生。
一方面工厂跟大量的口腔医院和独立诊所合作,所以业内谁口碑好谁口碑差,工厂最清楚不过。
你找到工厂,工厂会提供你所在地的口腔医院和诊所清单,上面会有好几家,这个时候就是让你自己选。
注意⚠️!!这里最重要的信息差是,工厂最清楚哪家口腔医院靠谱哪家不靠谱,如果你不问,工厂通常不会主动跟你说的!!!
所以这时候,你一定要多问几句,说清楚你的诉求,就是找一个靠谱的医生:
『方便帮我推荐某某地区技术和口碑最好的牙医吗?』
这个时候工厂才会亮出王牌,告诉你哪一家哪一位牙医最靠谱。工厂也是需要正向反馈的。
另一方面,因为省略牙医中间抽成这一环节,所以同样品质的假牙,会便宜非常多。
在哪里找到源头工厂?除了口腔业内人推荐,还有一个大家经常接触的渠道,就是淘宝。就直接搜假牙/全瓷牙/牙冠,找工厂店直接聊就可以。
#内幕消息
深圳这家直播带货公司,一个主播都不养,但是全中国的主播都给他卖货,今天聊的这位老板空手套白狼的功力极其深厚,他名义上是一家直播带货的公式,实际自己一个主播都不养,但销售额确是干到了 4 个亿。
跟这位老板聊完之后,我就发现他的核心点其实在于上下游的串联模式,非常的精妙,我来分享给你。先来说他是怎么去搞定主播的,很巧妙,他自己不培养主播,但是在全平台疯狂的联系已经在直播间有流量的主播给他们供货,如今他们已经有了3万名的主播在给他们卖货,而且这个数据还在以每月数千名主播的增长速度在增加。你看这是一个渠道铺货,逻辑是 2B 的,而不是 2c的。以前实体门店能卖货就把货铺给实体门店,现在主播能卖货就把货铺给主播呀。
那他的这个产品是怎么搞定的呢?抄爆款,超全网的爆款,绝对不自己开发产品,就是看平台的后台的数据,找到目前正在火热的销量靠前的爆款,直接拿过来找工厂 OEM 代价换成自己的品牌。你为啥生产出来的产品不好卖?不是爆款呀?那怎么出来爆款?拿别人的爆款再来一遍,你的就是爆款。那问题又来了,怎么去搞定3万名主播呢?这才是他的核心,他有一支 300 人的阿米巴商务团队,每天都在把所有的平台能卖货的主播加到私域,然后寄样品,搞关系。 300 人商务团队一个人搞定 100 个主播,就是3万名主播在给你卖货。
但是根本性的问题来了,因为像商务团队会拼命的去开发主播,主播又会拼命的给你卖货,关键点在于最后的分钱机制,它是这样去设计的,给带货的主播留出来30%,给阿米巴商务团队小组留出来20%,而真正的产品成本控制在 20% 暴利产品,那么这样计算下来,公司的利润率就还有20%,也就是说如果每个月 4000 万的销售额,会有 800 万的利润。
我始终关注的两个领域:
广告届的各种新锐、学界的前沿论文
广告人是我见过玩梗、融梗能力最强的一批人,非常擅长用一个点或一个概念击穿用户心智
前沿论文是为了拥有更高的视野,不能写着写着就把自己写到阴沟里去了
这两者结合后写出的文章,其实对大部分平台上的内容都可以进行降维打击。
当然目前我还没有这个能力,正在勤勉学习中
另外,分享一个最近刷到的很牛的案例:如何用文案卖出一顶复古前进帽
“把80年代戴在2023,聚会的姑娘主动和你聊天”
每每刷到牛掰的文案,我脑海中的那盏灯,好像突然又亮了一下,恍惚间回到几年前初入行时
要让自己的人生,多一些热泪盈眶的瞬间啊
开个贴讲一下我知道的新疆往事,尽量隐去具体细节。消息来源为一手或二手,即当事人亲自给我讲的,和旁观者给我讲的所见。其实半实名冲浪过程中我也从来没隐瞒过自己来自新疆,我在那长大,至今也仍有很多联系。因为他们是以发牢骚的形式告诉我的,所以我觉得他们没必要骗我。信不信由你。
某食堂,因为菜刀报废,而去指定地点买菜刀以及完成实名制备案来不及,要准备饭点的菜,厨师就从家里拿了一把过来。于是整个机构从上到下一撸到底。具体撸到哪一层我没问。
体制内都被安排了“结对子”任务,即分配少数民族对子,需要每周去对子家住,名义上是帮助,实际上也是监视。尤其是家里有人进“学习班”,这个家庭就是重点关注的。相关报道可以去NYT搜
幸运的话可以分配到城里的对子,但也有分配到农村的。新疆非常大各位应该知道,每周来回奔波数百公里也不稀奇。这些任务不是本职工作,但必须完成,也不能占用工作时间。
他们被要求记录对子的情况,除了明面上的状况,还需要记录诸如家里是否有宗教元素的物品,是否有中文以外的书籍,家里说什么语言。做礼拜需要报告吗?拜托,没人敢做礼拜了。
这种折腾肯定双方都不愿意。围绕着检查和反检查,搞出很多花样。最开始还可以双方串通,不去对子家住,打电话检查的时候对子帮忙圆一下。后来改成上门检查,那就到了半夜离开回家。于是发展成半夜上门检查。
半夜检查的时候,比如3点,点到你名,你要5分钟下楼跑到小区门口。有的小区非常大,来不及跑到的就会被罚。
事业单位的对子都在本市,平时大部分时间可以在自己家。一些公务员更惨,要“下沉”,直接去几百公里外的南疆,别人家里一住就是一年。
此外还有其他慰问任务,比如看监控。监控室里不能带手机,不能闲聊,有监控监控室的,不定期点名。不管多晚,点到名就得立刻站起来,敬礼🫡并大声喊“到!” 有人因为姿势不标准or左手敬礼被罚。
数万体制内就这么住到少数民族家里,很多家里还没有男人(因为去集中营学习了),想想就知道会出事。于是发生了滚床单的情况。为了防止此类事件再次发生,改为每次入住需要2个人。这些对子本来就穷,家里也没有什么客房,结果还得为两个陌生人准备床铺。
所有这些任务不是占用工作时间的,工作要做,结对子也要结。那岂不是得996了?那你就错了,996还能休息一天,他们全年无休。新疆还经常搞“大干100天”之类的折腾活动,100天不能休息。
小结:这些还只是我还记得的。这些人还都是体制内,都是汉人。你可以换个视角,带入被结对子的人试试。家里有人被抓,什么时候放出来不知道。然后还有陌生人每周都住到自己家里。你什么感觉。
高强度的“工作”和内耗,接连不断的政治学习,让很多人精神出现问题。所以在全国都在考公的时候,只有新疆公务员想的是如何辞职。我们那有个人才引进的小伙,都分了房,老婆也来了。结果来了就赶上疫情,长期高强度干那些没意义的工作。最后人家直接跑路,档案房子都不要了,以后也不打算进体制了。
自治区官方语言是两种这个应该都知道。招牌上的语言都是双语。但前几年开始我们那招牌上所有的维文都被删除,甚至是直接涂抹掉。原先维语音译的店名也改成了纯汉语名。但我只在该城市见到这种现象,其他城市都没有这样做。
最开始反极端宗教,禁止穿蒙住整个脸的好几种服饰。但随着逐渐加码,男性蓄须也成极端宗教了。开始是只允许老人蓄须,不知从什么时候起年轻男性也不能留胡子了,还不是那种大胡子,络腮胡都危险。你们可以去看各种新疆旅游vlog,看能不能找出一个大胡子出来。
1、没成长性的工作能糊弄尽量糊弄,没必要消
耗所有精力。你的工作也许就没有你想的那么重
要,做到65分和90分对单位影响不大,也给下一
次留有余地,工作之余,多陪陪家人,学习一些
有用的知识,兼职去做一些副业。
2、业余时间多看商业营销社会学心理学方面的
书籍,提升自己的思维认知,不要看那些情情爱
爱无病呻吟的书,看错书比吃错药更可怕。
3、尽量别去打工,实在不行就一边打工一边找
个靠谱的产品卖起来,只要你开始卖东西,就会
快速进入到最真实的社会模式,这样你成长速度
才会最快能看到最真实最客观的世界。
圆桌:对话奇绩创坛合伙人——探索创业之路的守正出奇
出席:毛圣博Peter、李晨啸race、林沅霖、徐律涛
YC 创立:Paul 05 年创立 YC,YC 在哈佛大学举办第一期夏令营,Sam 是当时的第一期。
模式:CoFounder as a service,创始人为先,先投资后加速,没有对赌。每年投资超过 100 多个项目,覆盖 20 多个前沿科技领域,喜欢投怪的项目。核心解决 PMF 问题。每周与合伙人一起解决问题 Office Hour 和 Group Office Hour。大咖闭门分享。路演日,面对上千个投资人。Bootcamp,针对早期创业的核心问题组织专题学习。产品日,帮助入营项目对接产业链上核心生态企业。
第一场
王ZY:19级信电,目前在华为。曾经在阿里云做 OAM 实习。想法:大模型需要很高的算力资源,希望做边缘计算,面向机器人的 AI 云上推理服务平台。主要问题:需求是否是真实的?如何找 CoFounder?
毛:很多人会拿着锤子找钉子,需要立刻去找用户聊,最好现场让用户看着开发,问卷需要但往往不真实而且水平比较低,做 AB 测试,扩大调研范围。可能大型企业不需要,看中型企业或者小型企业。toC最好有 demo 看用户是否点了那个button,混进竞争对手的用户群看用的最多的功能和最不爽的功能,做 10 倍提升。还可以调研上市公司,大公司其实是软柿子,因为他们调头比较麻烦。
Race:我们做 toC,共创社区。我的方法不是很通用性,自己是一个创作者。当时做 StepBeats,下载百万级,苹果编辑推荐,当时用户留存比较难,发现自己共情能力比较强但服务用户的意愿不强,发现创业是加杠杆,宁可不创业也想做,从自己的兴趣爱好出发,自己是自己的产品的用户。
沅霖:站到客户旁边,用户不需要服务器而是需要能让自己的产品发布上线,所以做了 pass。我们找到的用户可能是幸存者偏差,不是更广大用户的代表,即使自己是自己产品的用户。我们可能不需要扩大垂直服务的领域,不需要满足全部用户的需求,我们需要定义我们的用户范围。用户画像定义清楚后,假设自己产品已经完成了,看之后的增长能否找到稳定的获客渠道。
毛:还是和用户聊的太少,然后需要确定好用户范围,然后可复制性(PMF,YC认为PMF非常难,需要1-4年,其实做到PMF就能上市)
LT:解决LLM可用到可商用的最后一步。黄铮说:做正确的事情,把正确的事情做对(?)。Qi,人总是会变的。我们要找到自己的价值观,然后看这个价值观能否和做的事情兴趣匹配,不需要直接找一件事。可复制性用笨办法,保持平常心,每周找10个用户。找到一个事情作为起点,不要抱很大的执念,然后用笨办法慢慢找客户。
毛:People Mission Fit,不是自己的喜欢的事情很难坚持。大学生第一个想法靠谱概率很低,但是可能副产品可能就跑出来了。很多项目都是撞出来的,但是需要在路上,很多公司 Pivot 非常多次。旷视第一天做游戏,后来是一家安防公司。Insta360 一开始做在线直播,后面做运动相机。
毛:第二个问题怎么找 CoFounder。成功率最高的 CoFounder 就是学校同学。负担小,机会成本很低,失败对于再创业或者打工都很有用。首先要了解自己,我的长板和短板,核心团队需要有乐观的人和悲观的人,Founder 人数 2-3 比较好,因为很多人会跟不上。股份不能平分,人数最好不多于 4 人,找和自己互补的人,把自己的长板发挥到极限。
LT:打互联网+认识race。信任关系的构建很困难,大学是一个比较好的地方,有信任基础;广撒网,在各个平台发JD,最后找到的还是浙大的,没有捷径;找任何人不需要把他作为一辈子创业伙伴,要很好直率地表达分歧
YL:找 CoFounder 比较单纯,在外包开发认识。找 CoFounder 很放心,足够了解,愿意能放弃其他选择来参与,不需要找一个技术特别强的,而是要找一个信任的、能坚持的,退路不多,不喜欢打工不想当公务员抗压能力很强,或者找不到工作职业技能找不到匹配的
Race:也一直在探索,没有 BestPractice。自己要对自己有 100% 的信任和坦诚,然后找 CoFounder 也要找能对自己 100% 的信任和坦诚。
毛:找自己喜欢的,相处舒服
第二场
X:这一届进入奇绩,刚天使投融资完,便携的智能望远镜。研三,半辍学。加个几百个投资人,我们怎么对投资人做梳理和分类,如何巧妙地维持长期的关系。
毛:这个阶段投的是人,和投资人聊的是这件事能做大,提高可信度,对这个事情有多久多深的思考,有没有 insight 洞察。比如为什么不做一对一,最好的老师宁愿做一对多,一对一关键不是课讲的多好而是陪做作业(好的不需要讲差的讲不了,关键是中间的人的提高,而中间的人其实是自制力不强)。故事有insight,和人匹配,有可信度。梳理可以用database,比如企名片,看是否活跃。不可能所有投资人都喜欢你,但只需要有一个人愿意投你就可以。第一印象比较重要,然后看为什么不愿意投。如果是觉得金额比较高,那可以和他们说分两笔,然后定个milestone再发第二笔。如果是缀学我们会非常重视,说明决心非常强。
Race:我和投资人很坦诚。我是一个艺术家,我相信商业和科技是艺术接下来的必要,做到了 People Mission Fit。
YL:不用排斥找 FA。Founder 可能觉得我们对自己的产品最懂,但是 FA 是最了解 VC 的,他们掌握的信息更多,他们会帮你先补齐漏洞
LT:坚持自己的想法很关键。黄铮认为,创业也有小学中学大学。坚持找到能认可自己想法的人,“等你有进展”其实就是婉拒
毛:很多大的公司早期融资很困难,很多 VC 看好的做不大。当大多数人觉得不行但最终证明是对的事业(小概率)能做到非常大,比如拼多多。第一性原理。心要大。奇绩报名表:你有没有什么不同的idea别人很不同意但你很坚持
Q&A
做跨境电商,比如东南亚最近的情况非常危(印尼封禁 TikTok),想问下这个赛道
大走势是:供应链转到东南亚,会导致东南亚发展变快,最好是实地跑一趟,待个几周的时间。没有调研没有发言权现在做复刻数字人,目前刚拿到天使,这个市场怎么看?
很多公司融的越好就容易挂,扩张可能过快,心态比较膨胀。数字人是一个很大的机会,toC 陪伴,比如 minimax 的星野(?)。需要回归第一性原理,找到核心需求,愿不愿意付费,愿不愿意长期付费,比如旅游很低频,不要做低频生意,携程主打商务。做偶像虚拟人,需要多找年轻人找 CoFounder 问题,没有找到特别好的idea的时候怎么找人,或者说idea和人的优先级
事和人可遇不可求,找到人没有idea可能先尝试做一些项目,先上牌桌,考察合伙人,骑驴找马。有好的idea更容易找人,说服人需要有故事,三套故事:投资人、员工和客户
race:我是想清楚再找人,但也可以找人一起想;YL:还是先找事情,但是找事情的最好的方法可能是找人,去看这个人在这个领域有没有需求;LT:想办法站到更高的地方去,比如找牛逼的人聊,提高自己的认知,不要脸,Qi特别讨厌觉得自己牛逼的人,其实牛逼的人很谦虚,可以找他们去聊他们很多会愿意。如果找人找事都没有可能得站到更高的地方去
观众:刚毕业的人认知极浅,建议找个领域扎进去
毛:不需要进入特别卷或者特别需要经验的领域,去找经验可能成为包袱的领域,比如大模型、社交,开发对年轻人有用的东西,toC,但是如果需要很深人脉、很深技术、很多资历(芯片)的领域不要做。年轻人做电商都不太适合。核心就是 make something people want,我们要 think differently,不要太乖,学习最好去当教授了
用户输入需求,输入场景和面临的问题
推荐商品
生活上也好
大件上也好
做成硬件设备免费送到家里
语音输入,生成商品
收广告费
先只要品类品名回复(买关键词热度、商家seo优化)
积累用户
然后推荐平台甄选
翻译软件词典工具截屏翻译
ocr
截屏功能足够好用,贴图、历史剪贴板
AI套壳应用如何把壳做厚?
1.一阶:直接引用Open ai接口,ChatGPT回答什么,套壳产品回答什么。卷UI、形态、成本。
2.二阶:构建Prompt。大模型可以类比为研发,Prompt可以类比为需求文档,需求文档越清晰,研发实现得越精准。套壳产品可以积累自己的优质Prompt,卷Prompt质量高,卷Prompt分发。
3.三阶:Embedding特定数据集。把特定数据集进行向量化,在部分场景构建自己的向量数据库,以达到可以回答ChatGPT回答不出来的问题。比如垂直领域、私人数据等。Embedding可以将段落文本编码成固定维度的向量,从而便于进行语义相似度的比较,相较于Prompt可以进行更精准的检索从而获得更专业的回答。
4.四阶:微调Fine-Tuning。使用优质的问答数据进行二次训练,让模型更匹配对特定任务的理解。相较于Embedding和Prompt两者需要消耗大量的Token,微调是训练大模型本身,消耗的token更少,响应速度也更快。
一个AI应用产品如果停留在做一阶和二阶,注定是个门槛极低的产品,没有任何壁垒。
而什么场景,何时以及如何使用三阶和四阶的能力,是个关键性的问题。
用户最爱转发的内容有三种,第一种叫喜闻乐见,第二种叫感同身
受,第三种叫对我有用,它们的共通点都是与我有关。
找对原产地,立省一个亿。
买好货就靠源头直发。比如买包认准狮岭,买牛仔裤选新塘,买童装找湖州织里,买泳衣就是葫芦岛,买假发选许昌。还有潮汕内衣,南通四件套,浙江濮院羊毛衫,焦作雪地靴,揭阳睡衣,各种高质价比白牌。
中国社会一直存在一个“向何处去”的问题。两种i
能的前途严峻地摆在前面:一条是沿着完善市场经济
的改革道路前行,限制行政权力,走向法治的市场经
济;另一条是沿着强化政府作用的国家资本主义的道
路前行,走向权贵资本主义的穷途。中国经济发展的
过程就成为一场两种趋势谁跑得更快的竞赛。
#董宇辉,年羹尧,韩信的剧本,2500年前就写好了
原创 碧树西风 记忆承载 2023-12-25 07:31 发表于浙江
这个话题我第一天就写明白了,事后一直有读者问,一直追问。
非要我把话说透了,不是东方不允许有这么牛B的人物,而是大自然就不允许。
2500年前,老子出函谷关的时候,没钱交过路费,留下一本书,5000字。
这里面有一句话,重为轻根,静为躁君。是以圣人终日行不离辎重,虽有荣观,燕处超然。
这一句话就道尽了后来韩信,年羹尧,董宇辉所有人的命运。
如果你光看性格,这些人的性格是不一样的。
韩信是一个技术男,他就是直了点,如果非要说他有什么做错的地方,无非问刘邦讨要了一个齐王。
年羹尧也是一个直男,说到底就是没有帮着雍正推行他那些摊丁入亩之类的。
至于董宇辉,这小伙儿真没啥明面上的问题,人家够老实了,够憨厚了,够识趣了,够配合了。
所以古往今来,你看那么多书,那么多厚黑学之流给你评价分析人物性格,说到底,都是扯淡的。
这事儿跟性格没关系,你让董宇辉这个老实性格穿越过去做韩信,做年羹尧,一样的结局,一样。
为什么?
就是老子给你讲的那句话。
你读懂了这句话,就不会有这些问题。
重为轻根,这是哲学话题么?不,这是物理现象。
老子在给你讲什么?在给你讲牛顿三大定律。
咱们很容易想明白这件事,一个不倒翁,为什么不倒?
因为重的那头在下面,轻的那头在上面。
那么反过来,假如这个不倒翁重的那头在上面,轻的那头在下面,它能保持吗?能吗?
它不能,它一定会倒的,早晚会倒的,明白不?
一个国家,不可能长期保持外强中干,外强中干,早晚洗牌。
安史之乱,不是偶然,是必然,只要外强中干了,就一定会乱,无非谁先发起而已。
如果是中先发起,这叫什么?这叫削藩。
你看汉朝,无论是平定七国之乱,还是推恩令,实际上都是主动发起削藩。
就是这个不倒翁,它想要恢复平衡态,它就一定要回到中强外干。
到了唐朝,安史之乱无非是换了一个发起对象,有过历史经验了,哪怕安禄山没有读过道德经,他也晓得外强中干不能长久。
他如果不想被削藩,就要怎么样?
就一定要主动修改自己的生态位,俗称安禄山自己要去做那个中,要和唐玄宗彼此对调,换一个位置。
这件事要是做成了,那么从此姓李的改姓安。
这件事没有做成,唐朝后期一直都是外强中干,于是怎么样?于是就要结束,宋就来了。
宋代动辄东京汴梁城里聚集着号称百万禁军,林冲百万禁军教头的名号,就这么来的。
宋代要解决外强中干,因为它知道,那样不是平衡态。
你只要能够懂牛顿三大定律,你只要能够懂老子的这四个字,重为轻根,你怎么都能想明白这点事儿。
这和性格没有关系的,你让圣母特蕾莎修女去坐韩信,去坐年羹尧那个位置,结果是一样的。
这和情商也没关系,你不要认为情商是万能的,这不可能。
俗称那个生态位一定是那样的结局,谁坐一定,除非怎么样?除非你换个生态位。
韩信如果取代了刘邦,如果自己去坐刘邦的生态位,外强中干就消失了,同理可得,韩信如果被刘邦咔嚓了,外强中干也消失了。
只有消失,才能怎么样?才能恢复到稳定态,这就是老子描述的,重为轻根。
重的一定要在下面,轻的一定要在上面,这样才能是个不倒翁。
你说韩信又不想取代刘邦的生态位,又不愿意被刘邦咔嚓,那怎么做?
只有一种办法,就是主动把自己的生态位给咔嚓了嘛。
张良就是这么做的。
我不要你的生态位,我也不要我的生态位,我啥都不要了,我只要命,我退出游戏,我退出江湖,我退休,行了吗?
张良很清楚,刘邦不是和你的命有仇,而是重为轻根这件事,迫使他必然要解决外强中干的生态位。
他是冲你生态位去的,不是冲你的命。
如果你是外强,你必然要被解决。如果你既不想取代他,又不想被解决,那么就主动配合他杯酒释兵权,主动解决自己的生态位。
你现在看到对手了?
你的对手不是刘邦,你的对手是牛顿,是牛顿三大定律呀。
你不可能坐在韩信的生态位上长长久久,这不是臣妾真的做不到,这是牛顿也真的做不到啊。
当韩信既不肯退休,也不肯取代刘邦的时候,他的下场就和年羹尧是一样的了。
这和他的性格,和他的情商,和他做的具体事情无关,这是牛顿三大定律。
他哪怕每件事都做对,也没用,他哪怕抱着刘邦的大腿哭,说,邦哥,我是你异父异母的亲兄弟,也没用。
你想一想,汉景帝,汉武帝削藩的那些诸侯,有哪个不姓刘?
大家都是同族兄弟,不一样要干你么?
朱元璋大封诸子,那是为了解决淮西名将这些外强中干的问题。
对于朱元璋来说,儿子是亲生的,在他看来,儿子强不叫外强,淮西将领强才叫外强。
可是等朱元璋的孙子上来,叔叔们可就从内,变成外了。
于是朱元璋的孙子和叔叔们必然发生矛盾,只不过这次易主了,叔叔这个外做了中,孙子这个中,跑去出家了。
但是,最后能够重新达成平衡态,不还是老子的那四个字么?
重为轻根。
你必须要恢复到这个状态。
所以老子告诉你,告诉你什么?
告诉你如果你想要燕处超然,要怎样?要终日行不离辎重。
你时时刻刻都要掂量掂量轻重啊。
你一旦背离了那个重,这个不倒翁,一定倒的。
就这么简单一个道理,老子是文科生么?不,标准的理科生。
这哥们力学没毛病,妥妥的。
我们很多读者,你对这个世界的理解,太偏文科了,你真以为为人处事有啥用?
那玩意儿只是些皮毛。
你所有的皮毛要基于那个物理原理呀,老子这个人,他出生太早了,他没有发明物理这个词儿。
但是他解释了,他说了自己是在阐述道。
而且专门讲,名可名,非常名,你不要执着于名,名就是定义,等几千年后,你学了牛顿的知识,回头发现和老子相通,再正常不过。
这就是早年的物理学,无非他不叫个物理。
你的那些为人处事的皮毛,基于什么?基于什么?
基于你对基础科学的掌握。
重为轻根,这就是基础科学,本末一旦倒置,必然不稳。
外强中干,亲兄弟也维持不了,何况俞敏洪和董宇辉呢?
这事儿与人品毫无关系,你把俩圣人摆在他俩的位置上,结局是一样的。
要么削藩成功,要么上演朱棣的故事。
明白么?起作用的是那个物理呀。
你以为老子是厚黑学那点破水平,给你讲两句人性?
根本不是。
他从一开始就告诉你了,人法地,地法天,天法道,道法自然。
你再牛,你不过是个人,你得法地,地还得法天,天还得法道,道还得法自然呢。
你把一个不倒翁给我倒过来瞧瞧?你能坚持多久?你一辈子不松手?
你只要一松手,它就倒,就会恢复重为轻根的自然现象。
这就是你改不了的东西。
不是说真相不存在,而是真相没有人给你串起来。
你的物理老师只给你教万有引力,你的历史老师只给你教韩信,景帝削藩,安史之乱,只让你记住时间,事件,人物,你的政治老师只是告诉你,老子?批判一下就得了。
他们每个人都只管自己那门课,没人给你把知识串起来。
这也不是他们的错,而是大部分情况下,普鲁士教育教到这个水平就够用了,反正是培养产线工人的,要懂那么多干嘛?
教育要紧着什么?要紧着需求。
当下随着各种985硕士的涌入,快递行业正在迅速升级为知识密集型产业。
一个人过于通透,不见得有利于送好快递。
而且一个人过于通透,又不得不去送快递的时候,这事儿就更麻烦了。
窦太后当年做文帝皇后的时候,她的兄弟们骤然封侯,周勃等老功臣不安,怕再现吕后故事,于是聘人悉心教导这几个外戚。
这是什么?这就是当你做了高管之后,读MBA的重要性。
反过来,没有高管的位置要给你,你以为读MBA就会被提拔?想什么呢。
学了MBA,只能让你不安分守己,不愿意加班,没心思写好代码。
这两天很多人都让我写同一件事,我不想写,以后也不会写,因为有些事儿,你知道了,又解决不了,那还不如不知道。
那句话怎么说来着?当你不知道的时候,你才会觉得老板画的大饼真香,吃不完,真的吃不完…….
1.保持受众思维:这一年你可能做了很多事,很愿意趁这个机会把自己的功劳苦劳都讲出来,但事实是你会超时,而且受众听不懂,听不懂自然反馈差效果差。
受众之所以听不懂,一个是参加的同事老板可能和你的业务确实没有交集,共鸣不起来理解也费劲。一个是老板们更聚焦业务思维更加宏观,如果你开始在会上讲需求实现,聊方案细节,讲具体的东西他们可能真的不知道。整场分享下来,可能是在自己的流水账上自嗨。
2.不要陷入细节:具体做的事儿是要讲的,否则就是空中楼阁,老板觉得你可能啥也没干…但要有结构有轻重的讲。一个事儿能聊的无非是背景、价值、需求范围、挑战、做了什么以及怎么做的、结果、反思。我们在做了什么和怎么做的上面付出了太多精力,所以理所当然想把这部分更多呈现给受众,这没有问题,但问题是会不自觉陷入过分的实现细节的讲述。但事实上,未亲自接触过事情的人并不能够感同身受。这并不是prd评审。
3.娓娓道来:在时间上一定要保持松弛感,机关枪一样疯狂输出只是自我陶醉,只是满足了自己要把内容讲完的任务感,完全没有顾忌听众。听众本来就理解不了,还一直二倍速接受,效果能好就怪了。要娓娓道来,有给别人讲故事给别人介绍的感觉。
4.文本内容的组织:文本内容一定注意结构化,这是你认知和思路的体现,你怎么认识你全年工作的,怎么认识自己的职责范围,自己的工作价值,你怎么认识这场述职的,在结构上其实都体现出来了。
1.Java基础篇(阿里、蚂蚁、字节、携程、快手、杭州银行等)
问题:HashMap的底层实现原理
答案:
在jdk1.8之前,hashmap由 数组-链表数据结构组成,在jdk1.8之后hashmap由 数组-链表-红黑树数据结构组成;当我们创建hashmap对象的时候,jdk1.8以前会创建一个长度为16的Entry数组,jdk1.8以后就不是初始化对象的时候创建数组了,而是在第一次put元素的时候,创建一个长度为16的Node数组;当我们向对象中插入数据的时候,首先调用hashcode方法计算出key的hash值,然后对数组长度取余((n-1)&hash(key)等价于hash值对数组取余)计算出向Node数组中存储数据的索引值;如果计算出的索引位置处没有数据,则直接将数据存储到数组中;如果计算出的索引位置处已经有数据了,此时会比较两个key的hash值是否相同,如果不相同,那么在此位置划出一个节点来存储该数据(拉链法);如果相同,此时发生hash碰撞,那么底层就会调用equals方法比较两个key的内容是否相同,如果相同,就将后添加的数据的value覆盖之前的value;如果不相同,就继续向下和其他数据的key进行比较,如果都不相等,就划出一个节点存储数据;如果链表长度大于阈值8(链表长度符合泊松分布,而长度为8个命中概率很小),并且数组长度大于64,则将链表变为红黑树,并且当长度小于等于6(不选择7是防止频繁的发生转换)的时候将红黑树退化为链表。
2.并发编程篇(顺丰、大华、字节等)
问题:Java实现多线程有几种方式
答案:
继承Thread类,只需要创建一个类继承Thread类然后重写run方法,在main方法中调用该类实例对象的start方法
实现Runnable接口,只需要创建一个类实现Runnable接口然后重写run方法,在main方法中将该类的实例对象传给Thread类的构造方法,然后调用start方法
实现Callable接口,只需要创建一个类实现Callable接口然后重写call方法(有返回值),在main方法中将该类的实例对象传给 Future接口的实现类FutureTask的构造方法,然后再将返回的对象传给Thread类的构造方法,最后调用start方法
线程池,首先介绍它的好处,然后再说它可以通过ThreadPoolExecutor类的构造方法来进行创建。
3.JVM篇(阿里、字节、蚂蚁等)
问题:请简述JVM的类加载过程
答案:
加载:通过一个类的全限定名来获取此类的二进制字节流,然后在内存中生成一个代表这个类的Class对象
验证:确保Class文件的字节流中包含的信息符合《java虚拟机规范》的全部约束要求,保证虚拟机的安全
准备:为类变量(即静态变量,被staic修饰的变量)赋默认初始值,int为0,long为0L,boolean为false,引用类型为null;常量(被staic final修饰的变量)赋真实值
解析:把符号引用翻译为直接引用
初始化:执行类构造器
使用:使用这个类
卸载:一般情况下JVM很少会卸载类,如果卸载类需要满足以下三个条件该类所有的实例都已经被垃圾回收,也就是JVM中不存在该类的任何实例加载该类的类加载器已经被垃圾回收该类的Class对象没有在任何地方被引用
4.Hadoop篇(阿里)
问题:MapReduce 中排序发生在哪几个阶段?这些排序是否可以避免?
答案:
一个 MapReduce 作业由 Map 阶段和 Reduce 阶段两部分组成,这两阶段会对数据排序,从这个意义上说,MapReduce 框架本质就是一个 Distributed Sort。
在 Map 阶段,Map Task 会在本地磁盘输出一个按照 key 排序(采用的是快速排序)的文件(中间可能产生多个文件,但最终会合并成一个),在 Reduce 阶段,每个 Reduce Task 会对收到的数据排序(采用的是归并排序),这样,数据便按照 Key 分成了若干组,之后以组为单位交给 reduce 处理。
很多人的误解在 Map 阶段,如果不使用 Combiner 便不会排序,这是错误的,不管你用不用 Combiner,Map Task 均会对产生的数据排序(如果没有 Reduce Task,则不会排序,实际上 Map 阶段的排序就是为了减轻 Reduce端排序负载)。
由于这些排序是 MapReduce 自动完成的,用户无法控制,因此,在hadoop 1.x 中无法避免,也不可以关闭,但 hadoop2.x 是可以关闭的。
5.Spark篇(美团、字节等)
问题:如何解决spark的小文件问题
答案:
通过spark的coalesce()方法和repartition()方法
降低spark并行度,即调节spark.sql.shuffle.partitions
新增一个并行度为1的任务,专门用来合并小文件
6.Flink篇(拼多多、联通等)
问题:Flink是如何支持流批一体的
答案:
Flink 使用一个引擎就支持了DataSet API 和 DataStream API。其中DataSet API用来处理有界流,DataStream API既可以处理有界流又可以处理无界流,这样就实现了计算上的流批一体(目前流批一体最大的问题在于存储的统一上)
7.Kafka篇(京东、携程等)
问题:kafka是如何保证精准一次性的
答案:
0.11版本之后,kafka提出了一个非常重要的特性,幂等性(默认是开启的),也就是说无论producer发送多少次重复的数据,kafka只会持久化一条数据,把这个特性和至少一次语义(ack级别设置为-1+副本数=2+ISR最小副本数=2)结合在一起,就可以实现精确一次性(既不丢失又不重复)。我大致介绍一下它的底层原理:在producer刚启动的时候会分配一个PID,然后发送到同一个分区的消息都会携带一个SequenceNum(单调自增的),broker会对<PID,partition,SeqNum>做缓存,也就是把它当做主键,如果有相同主键的消息提交时,broker只会持久化一条数据。但是这个机制只能保证单会话的精准一次性,如果想要保证跨会话的精准一次性,那么就需要事务的机制来进行保证(producer在使用事务功能之前,必须先自定义一个唯一的事务id,这样,即使客户端重启,也能继续处理未完成的事务;并且这个事务的信息会持久化到一个特殊的主题当中)
8.资源调度篇(快手、vivo、字节等)
问题:请简述yarn的工作流程
答案:
首先客户端提交任务到RM上,同时客户端会向RM申请一个application,然后RM会告诉客户端资源的提交路径(比如jar包,配置文件);然后客户端就会提交任务运行需要的资源到对应路径上,提交完毕后,就会向RM申请Appmaster。RM会将用户的请求初始化成一个task,放入调度队列中,接着就会有NM领取task任务并且创建container容器和启动Appmaster。
然后Appmaster会向RM申请运行MapTask的资源,假设有两个切片,RM就会将运行maptask任务分配给两个nodemanager,这两个nodemanager分别领取任务并创建容器;Appmaster向这两个NM发送程序启动脚本,分别启动maptask;Appmaster等待所有maptask运行完毕后,再次向rm申请容器,运行reducetask
程序运行完毕后,Appmaster会向RM申请注销自己
9.数据质量篇(微众、美团等)
问题:如何保障数据质量
答案:
完整性定义:完整性是指数据的记录和信息是否完整,是否存在缺失的情况。数据的缺失主要包括记录的缺失和记录中某个字段信息的缺失,两者都会造成统计结果不准确,所以说完整性是数据质量最基础的保障。案例:比如交易中每天支付订单数都在100万笔左右,如果某天支付订单数突然下降到1万笔,那么很可能就是记录缺失了。对于记录中某个字段信息的缺失,比如订单的商品ID、卖家ID都是必然存在的,这些字段的空值个数肯定是0,一旦大于0就必然违背了完整性约束。
准确性定义:指数据中记录的信息和数据是否准确, 是否存在异常或者错误的信息。案例:比如一笔订单如果出现确认收货金额为负值,或者下单时间在公司成立之前,或者订单没有买家信息等,这些必然都是有问题的。
一致性定义:一致性一般体现在跨度很大的数据仓库体系中,比如阿里巴巴数据仓库,内部有很多业务数据仓库分支,对于同一份数据,必须保证一致性案例:例如用户ID,从在线业务库加工到数据仓库,再到各个消费节点,必须是同一种类型,长度也需要保持一致
及时性定义:在确保数据的完整性、准确性和一致性后,接下来就要保障数据能够及时产出,这样才能体现数据的价值。一般决策支持分析师都希望当天就能够看到前一天的数据,而不是等三五天才能看到某一个数据分析结果;否则就已经失去了数据及时性的价值,分析工作变得毫无意义。案例:现在对时间要求更高了,越来越多的应用都希望数据是小时级别或者实时级别的。比如阿里巴巴“双11” 的交易大屏数据,就做到了秒级
10.大数据场景篇(腾讯、百度等)
问题:1亿个整数中找出最大的10000个数
答案:
首先想到的就是全局排序,那么需要判断内存是否能够装的下?110^94B = 4GB,需要4G的内存,如果机器的内存小于4G,显然是不行的
第二种方法就是分治法,将这1亿个数通过hash算法,分为1000份,每份100万个数据,找到每份数据中最大的10000个数,最后在10010000中找出最大的10000个数,最大占用内存为 10000004B = 4MB。从100万个数中找到最大的10000个数的方法是快速排序的方法,但是我们没有必要将这100万个数排序,只用找到前10000个数,大致的思路是:将第一个数字设置为基准元素,然后将这100万个数分为两堆,如果大于基准的堆的个数大于10000个,那么继续对该堆进行一次快速排序,如果此时大的堆的个数n小于10000个,那么在小的堆中找到前10000-n的数字。
第三种方法就是小顶堆,首先读入前10000个数来创建大小为10000的最小堆,建堆的时间复杂度是O(m),然后遍历后续的数字,并与堆顶元素(最小)进行比较,如果比堆顶元素小,则继续遍历后面的数字即可;如果比堆顶元素大,则替换堆顶元素并重新调整堆为最小堆。直至遍历完所有的数字,最后输出当前堆的所有数字就可以了。整体的时间复杂度是O(mn)
#1.Flink如何保证Exactly-Once
使用checkpoint检查点,其实就是 所有任务的状态,在某个时间点的一份快照;这个时间点,应该是所有任务都恰好处理完一个相同 的输入数据的时候。
checkpoint的步骤:flink应用在启动的时候,flink的JobManager创建CheckpointCoordinatorCheckpointCoordinator(检查点协调器) 周期性的向该流应用的所有source算子发送 barrier(屏障)。当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状态制作成快照,并保存到指定的持久化存储(hdfs)中,最后向CheckpointCoordinator报告自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理。每个算子按照 上面这个操作 不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败。
#2.Flink的双流Join分为哪几类
分为window join和interval join两种window join:将两条实时流中元素分配到同一个时间窗口中完成Joininterval join:根据右流相对左流偏移的时间区间(interval)作为关联窗口,在偏移区间窗口中完成join操作
#3.Flink是如何处理反压的
反压就是指下游数据的处理速度跟不上上游数据的生产速度,Flink处理反压的流程如下:每个TaskManager维护共享Network BufferPool(Task共享内存池),初始化时向Off-heap Memory中申请内存。每个Task创建自身的Local BufferPool(Task本地内存池),并和Network BufferPool交换内存。上游Record Writer向 Local BufferPool申请buffer(内存)写数据。如果Local BufferPool没有足够内存则向Network BufferPool申请,使用完之后将申请的内存返回Pool。Netty Buffer拷贝buffer并经过Socket Buffer发送到网络,后续下游端按照相似机制处理。当下游申请buffer失败时,表示当前节点内存不够,则逐层发送反压信号给上游,上游慢慢停止数据发送,直到下游再次恢复。
#4.Flink的watermark如何理解
简单来说,它就是一种特殊的时间戳,作用就是为了让事件时间慢一点,等迟到的数据都到了,才触发窗口计算。我举个例子说一下为什么会出现watermark?
比如现在开了一个5秒的窗口,但是2秒的数据在5秒数据之后到来,那么5秒的数据来了,是否要关闭窗口呢?可想而知,关了的话,2秒的数据就丢失了,如果不关的话,我们应该等多久呢?所以需要有一个机制来保证一个特定的时间后,关闭窗口,这个机制就是watermark
#5.Flink的窗口机制分为哪几类
分为Time Window、Count Window和Session Window三种时间窗口根据时间对数据进行划分,分为Tumbling Time Window和Sliding Time Window,其中滚动时间窗口会将数据流切分成不重叠的窗口,每一个事件只能属于一个窗口;滚动时间窗口中的一条数据可以对应多个窗口计数窗口根据元素个数对数据进行划分,分为Tumbling Count Window和Sliding Count Window会话窗口根据会话来对数据进行划分,简单来说,就是数据来了之后就开启一个会话窗口,如果接下来还有数据陆续到来,那么就一直保持会话;如果一段时间一直没收到数据,那就认为会话超时失效,窗口自动关闭
#6.Flink是如何处理迟到数据的
watermark设置延迟时间
window的allowedLateness方法,可以设置窗口允许处理迟到数据的时间
window的sideOutputLateData方法,可以将迟到的数据写入侧输出流
一、Flink相比传统的Spark Streaming有什么区别?
这个问题是一个非常宏观的问题,因为两个框架的不同点非常之多。但是在面试时有非常重要的一点一定要回答出来:Flink 是标准的实时处理引擎,基于事件驱动。而 Spark Streaming 是微批(Micro-Batch)的模型。
下面我们就分几个方面介绍两个框架的主要区别:
(1)架构模型
Spark Streaming 在运行时的主要角色包括:Master、Worker、Driver、Executor,Flink 在运行时主要包含:Jobmanager、Taskmanager和Slot。
(2)任务调度
Spark Streaming 连续不断的生成微小的数据批次,构建有向无环图DAG,Spark Streaming 会依次创建 DStreamGraph、JobGenerator、JobScheduler。
Flink 根据用户提交的代码生成 StreamGraph,经过优化生成 JobGraph,然后提交给 JobManager进行处理,JobManager 会根据 JobGraph 生成 ExecutionGraph,ExecutionGraph 是 Flink 调度最核心的数据结构,JobManager 根据 ExecutionGraph 对 Job 进行调度。
(3)时间机制
Spark Streaming 支持的时间机制有限,只支持处理时间。Flink 支持了流处理程序在时间上的三个定义:处理时间、事件时间、注入时间。同时也支持 watermark 机制来处理滞后数据。
(4)容错机制
对于 Spark Streaming 任务,我们可以设置checkpoint,然后假如发生故障并重启,我们可以从上次 checkpoint 之处恢复,但是这个行为只能使得数据不丢失,可能会重复处理,不能做到恰一次处理语义。
Flink 则使用两阶段提交协议来解决这个问题。
二、Flink的监控页面,有了解吗,主要关注那些指标?
Flink 主要关注的有:
(1)Flink 任务运行状态
(2)Flink checkpoint 状态统计
(3)taskmamger的状态,内存使用情况以及垃圾回收情况
(4)Flink 的 metrics 是 Flink 公开的一个度量系统,metrics 也可以暴露给外部系统,通过在 Flink 配置文件 conf/flink-conf.yaml 配置即可,Flink原生已经支持了很多reporter,如 JMX、InfluxDB、Prometheus 等等。我们也可以自定义指标通过 metric 收集,实际开发时经常需要查看当前程序的运行状况,Flink 提供了 UI 界面,有比较详细的统计信息。
三、你们的Flink集群规模多大?
大家注意,这个问题看起来是问你实际应用中的Flink集群规模,其实还隐藏着另一个问题:Flink可以支持多少节点的集群规模?
在回答这个问题时候,可以将自己生产环节中的集群规模、节点、内存情况说明,同时说明部署模式(一般是Flink on Yarn),除此之外,用户也可以同时在小集群(少于5个节点)和拥有 TB 级别状态的上千个节点上运行 Flink 任务。
四、Flink如何保证精确一次性消费
Flink 保证精确一次性消费主要依赖于两种Flink机制
1、Checkpoint机制
2、二阶段提交机制
(1)Checkpoint机制
主要是当Flink开启Checkpoint的时候,会往Source端插入一条barrir,然后这个barrir随着数据流向一直流动,当流入到一个算子的时候,这个算子就开始制作checkpoint,制作的是从barrir来到之前的时候当前算子的状态,将状态写入状态后端当中。然后将barrir往下流动,当流动到keyby 或者shuffle算子的时候,例如当一个算子的数据,依赖于多个流的时候,这个时候会有barrir对齐,也就是当所有的barrir都来到这个算子的时候进行制作checkpoint,依次进行流动,当流动到sink算子的时候,并且sink算子也制作完成checkpoint会向jobmanager 报告 checkpoint n 制作完成。
(2)二阶段提交机制
Flink 提供了CheckpointedFunction与CheckpointListener这样两个接口,CheckpointedFunction中有snapshotState方法,每次checkpoint触发执行方法,通常会将缓存数据放入状态中,可以理解为一个hook,这个方法里面可以实现预提交,CheckpointListyener中有notifyCheckpointComplete方法,checkpoint完成之后的通知方法,这里可以做一些额外的操作。例如FLinkKafkaConumerBase使用这个来完成Kafka offset的提交,在这个方法里面可以实现提交操作。在2PC中提到如果对应流程例如某个checkpoint失败的话,那么checkpoint就会回滚,不会影响数据一致性,那么如果在通知checkpoint成功的之后失败了,那么就会在initalizeSate方法中完成事务的提交,这样可以保证数据的一致性。最主要是根据checkpoint的状态文件来判断的。
五、Flink如何做压力测试和监控?
我们一般碰到的压力来自以下几个方面:
(1)产生数据流的速度如果过快,而下游的算子消费不过来的话,会产生背压。背压的监控可以使用 Flink Web UI(localhost:8081) 来可视化监控,一旦报警就能知道。一般情况下背压问题的产生可能是由于 sink 这个 操作符没有优化好,做一下 优化就可以了。比如如果是写入 ElasticSearch, 那么可以改成批量写入,可以调大 ElasticSearch 队列的大小等等策略。
(2)设置 watermark 的最大延迟时间这个参数,如果设置的过大,可能会造成 内存的压力。可以设置最大延迟时间小一些,然后把迟到元素发送到侧输出流中去。晚一点更新结果。或者使用类似于 RocksDB 这样的状态后端, RocksDB 会开辟 堆外存储空间,但IO 速度会变慢,需要权衡。
(3)还有就是滑动窗口的长度如果过长,而滑动距离很短的话,Flink 的性能 会下降的很厉害。我们主要通过时间分片的方法,将每个元素只存入一个“重叠窗 口”,这样就可以减少窗口处理中状态的写入。
面试题:请说明Hive中Sort By、Order By、Cluster By,Distribute By各代表什么意思,以及具体应用?
1 问题分析
本题主要考察Hive里面的语法应用。
2 核心答案讲解
Order By
Order By会对输入做全局排序,因此只有一个Reducer(多个Reducer无法保证全局有序)。
然而只有一个Reducer,会导致当输入规模较大时,消耗较长的计算时间。
Sort By
Sort By不是全局排序,其在数据进入Reducer前完成排序,因此,如果用Sort By进行排序,并且设置mapred.reduce.tasks>1,则Sort By只会保证每个Reducer的输出有序,并不保证全局有序。
Sort By不同于Order By,它不受Hive.mapred.mode属性的影响,Sort By的数据只能保证在同一个Reduce中的数据可以按指定字段排序。
使用Sort By可以指定执行的Reduce个数(通过set mapred.reduce.tasks=n来指定),对输出的数据再执行归并排序,即可得到全部结果。
Distribute By
Distribute By是控制Map端如何拆分数据给Reduce端的。
Hive会根据Distribute By后面列,对应Deduce的个数进行分发,默认是采用Hash算法。Sort By为每个Reduce产生一个排序文件。
在有些情况下,你需要控制某个特定行应该到哪个Reducer,这通常是为了进行后续的聚集操作。Distribute By刚好可以做这件事。因此,Distribute By经常和Sort By配合使用。
Cluster By
Cluster By除了具有Distribute By的功能外,还兼具Sort By的功能。
但是排序只能是倒叙排序,不能指定排序规则为ASC或者DESC。
3 问题扩展
学习其他Hive语法,Hive Join等。
4 结合项目中使用
##面试题: Flink、Storm与Spark Stream的区别?
1 问题分析
本题考核的是面试人员对这三者的共同点/不同点,以及三者不同应用场景的理解。
2 核心答案讲解
相比于Storm ,Spark和Flink两个都支持窗口和算子,减少了不少的编程时间。
Flink相比于Storm和Spark,Flink支持解决乱序和延迟数据问题(在实际场景中,这个功能很好),这个功能是Spark没有的优点。
对于Spark而言,它的优势是机器学习,如果我们的业务场景中对实时要求不高,可以考虑Spark;
但如果要求很高,就考虑使用Flink,比如,对用户异常消费进行监控,如果这个场景使用Spark的话那么等到系统发现开始预警的时候(0.5s),罪犯已经完成了交易,可想而知,在某些场景下Flink的实时有多重要。
Spark Streaming在吞吐量上要比Storm优秀。
Storm在实时延迟度上,比Spark Streaming就好多了,前者是纯实时,后者是准实时。
而且,Storm的事务机制、健壮性/容错性、动态调整并行度等特性,都要比Spark Streaming更加优秀。
Spark Streaming,有一点是Storm比不上的,就是:它位于Spark整个生态技术栈中。
因此Spark Streaming可以和Spark Core、Spark SQL、Spark Graphx无缝整合,换句话说,我们可以对实时处理出来的中间数据,立即在程序中无缝进行延迟批处理、交互式查询等操作。这个特点大大增强了Spark Streaming的优势和功能。
3 问题扩展
有限数据集:数据大小有限(固定大小,比如固定的文件),用于批处理,这一类数据主要用于MapReduce,Hive,Pig,Spark等批计算引擎。
无限数据集:数据持续增长(属于无限大小,比如Kafka中的日志数据,总是有新数据进入,并且不知道什么时候结束或者是永远不结束),用于流式处理。
这一类数据主要用于Storm,Spark Streaming,Flink等一些流式计算引擎。
4 结合项目中使用
Storm
1)建议在需要纯实时,不能忍受1秒以上延迟的场景下使用。
比如实时计算系统,要求纯实时进行交易和分析时。
- 在实时计算的功能中,要求可靠的事务机制和可靠性机制,即数据的处理完全精准,一条也不能多,一条也不能少。也可以考虑使用Storm,但是Spark Streaming也可以保证数据的不丢失。
3)如果我们需要考虑针对高峰低峰时间段,动态调整实时计算程序的并行度,以较大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),我们也可以考虑用Storm。
Spark Streaming
1)如果不满足上述3点要求的话,我们可以考虑使用Spark Streaming来进行实时计算。
2)考虑使用Spark Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,即,如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询、图计算和MLlib机器学习等业务功能,且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能。
那么就应该推荐Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性。
Flink
1)支持高吞吐、低延迟、高性能的流处理
2)支持带有事件时间的窗口(Window)操作
3)支持有状态计算的Exactly-once语义
4)支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
5)支持具有Backpressure功能的持续流模型
6)支持基于轻量级分布式快照(Snapshot)实现的容错
7)运行时同时支持Batch on Streaming处理和Streaming处理
8)Flink在JVM内部实现了自己的内存管理
9)支持迭代计算
10)支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
面试题: INSERT INTO 和 INSERT OVERWRITE 的区别?
1 问题分析
本题主要考察面试者对插入数据和覆盖数据的基本使用。
2 核心答案讲解
INSERT OVERWRITE 会覆盖已经存在的数据,假如,原始表使用OVERWRITE 上的数据,先将原始表的数据Remove,再插入新数据。
INSERT INTO 只是简单的插入,不考虑原始表的数据,直接追加到表中。
3 问题扩展
INSERT INTO Partition时,如果分区不存在,会自动创建分区。
多个INSERT INTO Partition作业并发时,如果分区不存在,会自动创建分区,但只会成功创建一个分区。
如果不能控制INSERT INTO Partition作业并发,则只能通过预创建分区避免问题。
4 结合项目中使用
INSERT OVERWRITE 会覆盖已经存在的数据,如被覆盖的表中有3条数据和要插入的一条数据相同,那么覆盖后只会有1条数据;
INSERT INTO 只是简单的copy插入,不做重复性校验。
##面试题:根据什么对Hive表进行分桶分区?
1 问题分析
本题主要是考察面试者在日常开发中是否注重了表查询的效率问题,还有对数据的一些处理方案,依照这些考察面试者是否具备一名大数据人员的基本能力。
2 核心问题讲解
分区
在Hive Select查询中,一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中一部分数据,因此建表时引入了Partition概念。分区表指的是在创建表时,指定Partition的分区空间。
Hive可以对数据按照某列或者某些列进行分区管理,所谓分区我们可以拿下面的例子进行解释: 互联网应用每天都要存储大量的日志文件,几G、几十G甚至更大都是有可能。存储日志,其中必然有个属性是日志产生的日期。在产生分区时,就可以按照日志产生的日期列进行划分,把每一天的日志当作一个分区。 将数据组织成分区,主要可以提高数据的查询速度。至于用户存储的每一条记录到底放到哪个分区,由用户决定。即用户在加载数据时,必须显示指定该部分数据放到哪个分区。
分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说,桶是更为细粒度的数据范围划分。
Hive也是针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式,决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
1)获得更高的查询处理效率
桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。
比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
2)使取样(sampling)更高效
在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
3 问题扩展
如何创建分桶、分区?
hive>create table student(id INT, age INT, name STRING)
partitioned by(stat_date STRING)
clustered by(id) sorted by(age) into 2 bucket
row format delimited fields terminated by ‘,’;
4 结合项目中使用
在实际项目中,对于数据体量清晰且对于数据业务了解清楚后,依照基本规范选择进行分区还是分桶即可。
面试题:Spark技术栈有哪些组件,每个组件都有什么功能?
1 问题分析
本题旨在考察面试者是否了解Spark以及Spark的使用场景。
2 核心答案讲解
1)Spark Core:是其它组件的基础,Spark的内核,主要包含:有向循环图、RDD、Lingage、Cache、Broadcast等,并封装了底层通讯框架,是Spark的基础。
2)SparkStreaming:(类似于storm)可以对实时数据流进行高通量、容错处理的流式处理系统,可以对多种数据源(如Kafka、Flume、Twitter、Zero和TCP 套接字)进行类似于Hadoop中的Map、Reduce和Join等复杂操作,将流式计算分解成一系列短小的批处理作业。
3)Spark SQL:Shark是Spark SQL的前身,Spark SQL的一个重要特点是其能够统一处理关系表和 RDD(弹式分布数据集),使得开发人员可以轻松地使用SQL命令进行外部查询,同时进行更复杂的数据分析。
4)BlinkDB :是一个在海量数据上运行交互式 SQL 查询的,大规模并行查询引擎,它允许用户通过权衡数据精度来提升查询响应时间,其数据的精度被控制在允许的误差范围内。
5)MLBase是Spark生态圈的一部分专注于机器学习,让机器学习的门槛更低,让一些可能并不了解机器学习的用户也能方便地使用MLBase。
MLBase分为四部分:MLlib、MLI、ML Optimizer和MLRuntime。
6)GraphX,Spark中用于图和图并行计算。
3 问题扩展
Spark的有几种部署模式以及每种模式特点?
4 结合项目中使用
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。
需要反复操作的次数越多,所需读取的数据量越大,受益越大;
数据量小,但是计算密集度较大的场合,受益就相对较小。
由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用。
例如,Web服务的存储或者是增量的Web爬虫和索引。
即,对于那种增量修改的应用模型并不适合。
数据量不是特别大,但是要求实时统计分析需求。
面试题:Spark 如何防止内存溢出?
1 问题分析
Spark,不同于MapReduce的是:Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce算法。
2 核心答案讲解
(1)Driver端的内存溢出
可以增大Driver的内存参数:spark.driver.memory (default 1g) , 这个参数用来设置Driver的内存。
在Spark程序中,SparkContext,DAGScheduler都是运行在Driver端的。对应RDD的Stage切分也是在Driver端运行,如果用户自己写的程序有过多的步骤,切分出过多的Stage,这部分信息消耗的是Driver的内存,这时候就需要调大Driver的内存。
(2)Map过程产生大量对象导致内存溢出
这种溢出的原因是在单个Map中产生了大量的对象导致的。
例如:rdd.map(x=>for(i <- 1 to 10000) yield i.toString),这个操作在RDD中,每个对象都产生了10000个对象,这肯定很容易产生内存溢出的问题。
针对这种问题,在不增加内存的情况下,可以通过减少每个Task的大小,以便达到每个Task即使产生大量的对象Executor的内存也能够装得下。
具体做法:在产生大量对象的Map操作之前调用repartition方法,分区成更小的块传入Map。
例如:rdd.repartition(10000).map(x=>for(i <- 1 to 10000) yield i.toString)。
面对这种问题注意,不能使用rdd.coalesce方法,这个方法只能减少分区,不能增加分区,不会有Shuffle的过程。
(3)数据倾斜导致内存溢出
数据不平衡除了有可能导致内存溢出外,还有可能导致性能的问题,解决方法和上面说的类似,就是调用repartition方法重新分区,这里不再赘述。
(4)Shuffle后内存溢出
Shuffle内存溢出的情况可以说:大多是Shuffle后单个文件过大导致的。
在Spark中,Join,ReduceByKey 这一类型的过程,都会有Shuffle的过程,在Shuffle的使用,需要传入一个Partitioner,大部分Spark中的Shuffle操作,默认的Partitioner都是HashPatitioner,默认值是父RDD中最大的分区数,这个参数通过spark.default.parallelism控制(在spark-sql中用spark.sql.shuffle.partitions) , spark.default.parallelism参数只对HashPartitioner有效。
即:如果是别的Partitioner或者自己实现的Partitioner,就不能使用spark.default.parallelism这个参数来控制Shuffle的并发量了。
如果是别的Partitioner导致的Shuffle内存溢出,就需要从Partitioner的代码增加Partitions的数量。
(5)Standalone模式下,资源分配不均匀导致内存溢出
在Standalone的模式下如果配置了–total-executor-cores 和 –executor-memory 这两个参数,但是没有配置–executor-cores这个参数的话,就有可能导致此现象。
每个Executor的memory是一样的,但是cores的数量不同,那么在cores数量多的Executor中,由于能够同时执行多个Task,就容易导致内存溢出的情况。
这种情况的解决方法就是同时配置–executor-cores或者spark.executor.cores参数,确保Executor资源分配均匀。
(6)使用rdd.persist(StorageLevel.MEMORY_AND_DISK_SER) 代替 rdd.cache()
rdd.cache()和rdd.persist(Storage.MEMORY_ONLY)是等价的,在内存不足的时候rdd.cache()的数据会丢失,再次使用的时候会重算,而rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)在内存不足的时候会存储在磁盘,避免重算,只是消耗点IO时间。
3 问题扩展
Spark的内存管理
可以通过Spark提供的统一接口MemoryManager,存储内存和执行内存的管理,同一个Executor内的任务都调用这个接口的方法来申请或释放内存:
//释放存储内存
def releaseStorageMemory(numBytes: Long, memoryMode: MemoryMode): Unit
Spark数据倾斜的解决方案
解决方案一:使用Hive ETL预处理数据
解决方案二:过滤少数导致清晰的key
解决方案三:提高Shuffle操作的并行度
解决方案四:两阶段聚合(局部聚合+全局聚合)
解决方案五:将Reduce Join转整Map Join
解决方案六:采样倾斜Key并分拆Join操作
4 结合项目中使用
一个原则,你能使用的资源有多大,就尽量去调节到最大的大小(Executor的数量,几十个到上百个不等;Executor内存;Executor CPU Core)
增加Executor数量
增加每个Executor的内存量
增加每个Executor的CPU Core,也是增加了执行的并行能力。
面向业务的数据库设计
面向业务的数据库设计流程通常分为以下6个阶段1:
需求分析:分析用户的需求,包括数据、功能和性能需求。
概念结构设计:主要采用E-R模型进行设计,包括画E-R图。
逻辑结构设计:通过将E-R图转换成表,实现从E-R模型到关系模型的转换。
数据库物理设计:主要是为所设计的数据库选择合适的存储结构和存取路径。
数据库实施:包括编程、测试和试运行。
数据库运行与维护:系统的运行与数据库的日常维护。
1.项目经历
2.数仓分层
3.数仓执行引擎
4.Sql关键字执行顺序
5.Mysql索引引擎
6.Innodb和myisam区别
7.Flink基本算子
8.Map和flatmap
9.Keyby
10.数据倾斜 怎么定位
11.Hive分区表和非分区表
12.增加或删除字段
13.Hive内外部表
14.UDF
15.窗口函数
16.Redis数据结构
17.Java hashmap线程安全形式
18.简单SQL:所有得分高于90的学生、任意学科大于90
大数据面试
SQL调优有哪些?
通过建立索引对查询进行优化
对查询进行优化,应尽量避免全表扫描
应尽量避免在 where 子句中使用!=或<>操作符
对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引
应尽量避免在 where 子句中对字段进行 null值判断,否则将导致引擎放弃使用索引而进行全表扫描
尽量避免在 where 子句中使用 or 来连接条件
in 和 not in 也要慎用,否则会导致全表扫描
读写分离,分库建表 explain sql分析 sql 索引的使用和优化等方面
TailDir为什么可以断点重传?
tail-dir 使用flume内置json文件记录读取位置,实现了断点续传,避免了flume宕机后重启的脏数据问题。
Linux什么指令可以监听文件?
tail命令可以输出文件的尾部内容linux监视文件命令,默认情况下它显示文件的最后十行。它常用来动态监视文件的尾部内容的增长情况,比如用来监视日志文件的变化。
Kafka 都有哪些特点?
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
可扩展性:kafka集群支持热扩展
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发:支持数千个客户端同时读写。
请简述下你在哪些场景下会选择 Kafka?
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、HBase、Solr等。
消息系统:解耦和生产者和消费者、缓存消息等。
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
流式处理:比如spark streaming和 Flink
Kafka 的设计架构?
Kafka 架构分为以下几个部分:
Producer :消息生产者,就是向 kafka broker 发消息的客户端。
Consumer :消息消费者,向 kafka broker 取消息的客户端。
Topic :可以理解为一个队列,一个 Topic 又分为一个或多个分区,
Consumer Group:这是 kafka 用来实现一个 topic 消息的广播(发给所有的 consumer)和单播(发给任意一个 consumer)的手段。一个 topic 可以有多个 Consumer Group。
Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker上,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的id(offset)。将消息发给 consumer,kafka 只保证按一个 partition 中的消息的顺序,不保证一个 topic 的整体(多个 partition 间)的顺序。
Offset:kafka 的存储文件都是按照 offset.kafka 来命名,用 offset 做名字的好处是方便查找。例如你想找位于 2049 的位置,只要找到 2048.kafka 的文件即可。当然 the first offset 就是 00000000000.kafka。
Kafka 分区的目的?
分区对于 Kafka 集群的好处是:实现负载均衡。分区对于消费者来说,可以提高并发度,提高效率。
Kafka 是如何做到消息的有序性?
kafka 中的每个 partition 中的消息在写入时都是有序的,而且单独一个 partition 只能由一个消费者去消费,可以在里面保证消息的顺序性。但是分区之间的消息是不保证有序的。
Kafka Producer 的执行过程?
1,Producer生产消息 –> 2,从Zookeeper找到Partition的Leader –> 3,推送消息 –> 4,通过ISR列表通知给Follower –> 5, Follower从Leader拉取消息,并发送ack –> 6,Leader收到所有副本的ack,更新Offset,并向Producer发送ack,表示消息写入成功。
首先,Kafka会在ZooKeeper上查找该分区的所有副本中的Log End Offset(LEO)最大的那个Broker,也就是说,该Broker的副本中保存的数据最新。然后,将该Broker选举为该分区的新Leader节点。 如果有多个副本的LEO相等,则Kafka会优先选择在ISR(In-Sync Replicas)中的副本,ISR中的副本与Leader节点保持同步,因此可以保证数据的一致性。如果没有ISR中的副本,则选择所有副本中的第一个在线的Broker作为新的Leader节点。 总之,Kafka在重新选举新的Leader节点时,会优先选择最新的数据副本,并尽可能地保证数据的一致性。
kafka如何保证数据的一致性?
Kafka保证数据一致性的方式有很多,其中一个是通过使用分布式副本集。分布式副本集是一组Kafka服务器,它们在同一个集群中,共同维护一个副本。当消息被写入Kafka时,它会被复制到多个副本中,从而保证数据的完整性。如果其中一个副本失效,另一个副本可以接管它的工作。这样,Kafka就可以保证数据的一致性。
MySQL的存储引擎有哪些?
InnoDB存储引擎
MyISAM存储引擎
Memory存储引擎
Innodb的索引是怎么实现的?
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用”where id = 14”这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
MyISM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
HDFS的架构是怎样的?
NameNode(nn):就是Master,它是一个主管、管理者。
管理HDFS的名称空间;
配置副本策略;
管理数据块(Block)映射信息;
处理客户端读写请求。
DataNode:就是Slave。NameNode下达命令,DataNode执行实际的操作。
存储实际的数据块;
执行数据块的读/写操作。
Client:就是客户端。
文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传;
与NameNode交互,获取文件的位置信息;
与DataNode交互,读取或者写入数据;
Client提供一些命令来管理HDFS,比如NameNode格式化;
Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作;
Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode ;
在紧急情况下,可辅助恢复NameNode。
NN和2NN有什么区别?
2NN与NN的区别只缺少了一个正在编辑的日志文件
HDFS的HA怎么实现?
HDFS的NameNode为单一节点,为HDFS提供对外统一服务,这说明如果NameNode因为某些原因掉线了,那整个HDFS集群就会瘫痪。为了防止这种情况在生产环境中出现,就引入了高可用(HA)模式。 在HA模式中,一般由两个NameNode组成,一个是处于激活(Active)状态,另一个就处于待命(Standby)状态,处于激活状态的NameNode对外提供统一服务,而待命状态的NameNode则不对外提供服务,同时及时同步激活状态的NameNode。当激活的NameNode掉线了,待命的NameNode就马上切换状态,变成Active。
HDFS 的读和写?
如何读 流程图
当HDFS客户端需要读取一个数据文件的时候,首先会调用FileSystem的open()方法获取一个dfs对象(DistributedFileSystem)。
DFS通过RPC从NameNode中获取文件第一批块的位置信息后,会返回一个FsDataInputStream对象。
返回的FsDataInputStream会被封装成DFSInputStream(分布式文件系统输入流),里面提供了管理NameNode和DataNode输入流的方法。当客户端调用read()方法的时候,DFSInputStream就会找出离客户端最近的DataNode并连接。
找出DataNode后就会开始读取对应的数据块,数据开始流向客户端。
当第一个块读取完成后,就会关闭第一个块指向的DataNode连接,然后接着读下一个块。
当第一批块读取完成后,就会向NameNode获取下一批块的位置信息,然后继续读取。
当所有块都读取完成后,就会关闭所有的流。
当然,在实际情况下,想一直那么顺利的传输数据是不可能的,如果在读取数据的时候,DataNode和DFSInputStream发生异常的时候,那么DFSInputStream会尝试获取当前读取块第二近的DataNode节点,并会记录哪个DataNode发生错误,后面涉及到该出事DataNode读取的时候,就会自动跳过。 如果读取的块已经坏了,那么就会将这种情况汇报给NameNode,并且从其他DataNode读取该块数据。
如何写 看下面流程图:
和读操作一样,首先通过FileSystem获取一个DFS对象,并通过DFS对象来的create()方法来创建一个新的文件。
DFS通过RPC调用NameNode去创建一个新文件,NameNode在创建前会做一些额外的校验,如文件是否已经存在、客户端是否有权限创建文件等等。
前面的操作完成后,DFS会返回一个FsDataOutputStream对象,同样,FsDataOutputStream会被封装成DFSOutputStream(分布式文件系统输入流),同样,DFSOutputStream也提供了协调DataNode和NodeNode的方法。
当客户端开始写数据的时候,就会将数据块切分成一个个数据包,然后将这些数据包排成一条数据队列。
多个DataNode组成一条数据管道,当开始传输的时候,首先第一个数据包会传到数据管道的第一个DataNode,当第一个DataNode收到后会将这个数据包传给下一个DataNode。
DFSOutputStream除了数据管道外,还维护着另一个队列:响应队列,这个队列也是由数据包组成的,当DataNode收到数据块的数据包后,就会返回一个响应数据包,当管道中所有的DataNode都收到响应数据包的时候,响应队列才把对应的数据包移除。
客户端在写操作完成后,就会调用close()关闭输出流。
同时,客户端会通知NameNode把文件标记为已完成,然后NameNode会把文件写入成功的结果返回给客户端。这时整个写操作才完成。
当然,凡是涉及到节点之前的通信,都大概率会出现一些奇怪的问题,例如网络不可用啊、通信节点掉线啊等等,对于这种情况,写操作要比读操作要复杂一点,如果在写操作过程中其中一个DataNode发生错误,那么就有下面几个步骤来处理:
管道关闭。
正常的DataNode正在写的块会由一个新的ID,并且这个ID会汇报给NameNode,而失败的DataNode上发生错误的块就会在下次上报心跳的时候删掉。
失败的DataNode会被从管道中移除,而块中剩下的数据包会继续写入到管道里其他的DataNode上。
NameNode同时会标记这个块的副本数量少于指定值,那么会在后面将这个块的副本在其他DataNode上创建。
HBase是列式存储吗?行式存储和列式存储有什么区别?
在数据写入上的对比
行存储的写入是一次完成。如果这种写入建立在操作系统的文件系统上,可以保证写入过程的成功或者失败,数据的完整性因此可以确定。
列存储由于需要把一行记录拆分成单列保存,写入次数明显比行存储多(意味着磁头调度次数多,而磁头调度是需要时间的,一般在1ms~10ms),再加上磁头需要在盘片上移动和定位花费的时间,实际时间消耗会更大。所以,行存储在写入上占有很大的优势。
还有数据修改,这实际也是一次写入过程。不同的是,数据修改是对磁盘上的记录做删除标记。行存储是在指定位置写入一次,列存储是将磁盘定位到多个列上分别写入,这个过程仍是行存储的列数倍。所以,数据修改也是以行存储占优。
在数据读取上的对比
数据读取时,行存储通常将一行数据完全读出,如果只需要其中几列数据的情况,就会存在冗余列,出于缩短处理时间的考量,消除冗余列的过程通常是在内存中进行的。
列存储每次读取的数据是集合的一段或者全部,不存在冗余性问题。
两种存储的数据分布。由于列存储的每一列数据类型是同质的,不存在二义性问题。比如说某列数据类型为整型(int),那么它的数据集合一定是整型数据。这种情况使数据解析变得十分容易。相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗CPU,增加了解析的时间。所以,列存储的解析过程更有利于分析大数据
显而易见,两种存储格式都有各自的优缺点:
行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略;数量大可能会影响到数据的处理效率。
列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。
NN和2NN有什么区别?
NN和2NN的区别在于2NN是一个辅助节点,用于帮助NN进行元数据的备份和恢复。在传统的HDFS架构中,NN是单点故障,如果NN发生故障,整个文件系统将不可用。通过引入2NN并将元数据的备份放在2NN上,可以提供高可用性和容错能力。
HDFS的HA怎么实现?
HDFS的高可用性(HA)是通过在集群中启用多个NN来实现的。在这种配置下,会有一个Active NN和多个Standby NN运行,Active NN处理客户端请求并维护元数据,Standby NN则跟踪Active NN的操作并保持与其同步。如果Active NN失效,Standby NN可以快速接管并继续提供服务,以实现无缝的故障切换和高可用性。
HBase是列式存储吗?行式存储和列式存储有什么区别?
HBase是一种列式存储数据库。传统的行式存储数据库以行为单位存储数据,而列式存储数据库将数据以列为单位进行存储。这种存储方式在分析和聚合大量数据时表现出色,因为可以只读取需要的列数据,而不需要读取整行数据。此外,列式存储数据库还支持更高的压缩比和更快的查询速度。
介绍一下HBase的HA?
HBase的高可用性(HA)是通过在集群中启用多个RegionServer来实现的。每个RegionServer负责管理一个或多个Region(数据表的分片),而Master节点负责协调和监控整个集群。如果Master节点发生故障,可以通过选举新的Master节点来继续提供服务。同时,HBase还支持ZooKeeper来进行故障检测和集群协调。
项目里Hive用的是内部表还是外部表?它们的区别是什么?并说明为什么用外部表?
在项目中,使用的是Hive的内部表。内部表是Hive自己管理的表,其元数据和数据都存储在Hive的默认存储路径中。而外部表是在Hive中引用外部HDFS或本地文件系统上的数据,其元数据存储在Hive的默认存储路径,而数据存储在外部数据路径中。外部表可以使数据与Hive解耦,可以方便地在不同Hive实例之间共享数据,也可以方便地与其他数据处理工具集成。
介绍一下Hive数据倾斜?
Hive数据倾斜指在数据处理过程中,某些数据分布不均匀,导致部分计算任务消耗的时间远远超过其他任务的现象。这会导致整个任务的执行时间延长。针对此问题,可以采取一些优化措施,如使用MapJoin代替常规Join,增加数据的分区等。
介绍一下Hive的UDF函数?
Hive的UDF(User-Defined Function)函数是用户自定义的函数,用于在Hive中进行数据处理和计算。用户可以使用Java或其他编程语言编写UDF函数,并将其注册到Hive中,然后通过Hive的查询语句调用这些函数。UDF函数可以扩展Hive的功能,以满足特定的数据处理需求。
有没了解过开窗函数?介绍一下
开窗函数(Window Function)是一种在关系型数据库中进行分析函数计算的功能。它可以对查询结果的某个窗口进行聚合、排序、筛选等操作,并生成与原始查询结果相匹配的结果集。开窗函数通常与OVER子句一起使用,以指定窗口的范围和排序方式。
MySQL的存储引擎有哪些?Innodb的索引是怎么实现的?为什么用B+树?
MySQL的存储引擎有多种,常见的包括InnoDB、MyISAM等。其中InnoDB是一种事务安全的存储引擎,支持行级锁和MVCC,并提供了更好的并发性能和数据完整性。InnoDB的索引是通过B+树来实现的,B+树是一种多叉树结构,可以实现快速的查找和范围查询,并且对数据的插入和删除操作有较好的性能。
索引的作用
索引的作用是提高数据库的查询性能。通过在数据库表中创建索引,可以将数据按照特定的列或多列进行排序和组织,从而加快数据的查找速度。索引可以减少磁盘I/O和减少查询的数据扫描量,提高查询效率。
内连接是什么?
内连接(Inner Join)是一种数据库查询操作,用于获取两个表中共有的数据记录。内连接根据两个表中的连接条件,将满足条件的记录合并成一条记录,并返回结果。只有在连接条件满足的情况下,内连接才会返回结果。
有了解MVCC吗?介绍一下
MVCC(Multi-Version Concurrency Control)是一种并发控制机制,用于在并发读写场景中保证数据库的一致性和隔离性。MVCC通过给每个事务分配唯一的事务ID,并为每个修改操作创建一个新版本的数据,从而实现并发访问的数据可见性和一致性。在读操作中,可以根据事务ID和版本号来选择合适的数据版本,从而保证不会读取到由其他事务修改但未提交的数据。
SQL调优有哪些?
SQL调优主要包括以下几个方面:优化查询语句、适当创建索引、合理设计数据库表结构、适时进行表分区、优化数据库配置参数、适当缓存查询结果、使用批量操作等。
项目里的Flume是怎么用的?
项目中的Flume可以用来实时收集、聚合和传输大量的日志数据,并将其传输到其他的数据存储系统(如Hadoop、HBase等)。可以通过配置Flume的source(源)和sink(目标)来定义数据的输入和输出。
TailDir为什么可以断点重传?
TailDir可以监听指定文件夹中的文件变化情况,并将新增的文件或者文件中新增的数据传输到指定的目标。它实现断点重传的方式是通过记录每个文件的文件偏移量,当发生中断时,可以根据文件偏移量继续读取文件,从而实现断点重传。
Linux什么指令可以监听文件?
在Linux中,可以使用tail -f命令来监听文件的变化,并实时输出新增的内容。
Kafka的基本架构?
Kafka的基本架构由多个组件组成,包括Producer、Broker、ZooKeeper、Consumer等。Producer负责将数据发送到Kafka集群,Broker负责存储消息并处理消息的分发,ZooKeeper用于协调和管理Kafka集群的状态,Consumer负责从Kafka中读取数据。
Kafka的partition副本写数据是怎么写的?
Kafka的partition副本写数据是采用领导者-追随者模式。每个partition都有一个leader和多个follower,当Producer发送消息时,会将消息发送给对应partition的leader,leader将消息写入自己的日志,并同步给所有follower。一旦leader确认消息已写入多数follower的日志,就返回成功给Producer。follower会周期性地从leader拉取新的数据,并将其写入自己的日志。
Kafka副本的leader是怎么选出来的?
Kafka的副本的leader是通过选举机制选出来的。当leader出现故障或下线时,Kafka会从副本中选择一个新的leader,选举方式通常基于副本的优先级和可用性等因素进行选择。
有没有了解Kafka的架构设计?
Kafka的架构设计是基于分布式、高可用、高吞吐量和容错性。它采用发布-订阅消息模型,通过分区和副本机制实现高吞吐量和可靠性,同时借助ZooKeeper实现集群的管理和协调。
Java的有哪些集合?详细介绍一下实现过程?
Java中常见的集合包括List、Set和Map等。其中,List实现有ArrayList和LinkedList,Set实现有HashSet和TreeSet,Map实现有HashMap和TreeMap等。不同的集合实现方式有所不同,可以根据具体的场景和需求选择适合的集合。
ArrayList是怎么实现的?LinkedList是怎么实现的?ArrayList与LinkedList有什么区别?
ArrayList是通过数组实现的,它在内存中是一块连续的空间。LinkedList则是通过链表实现的,每个节点保存了当前元素的值以及指向前一个节点和后一个节点的引用。ArrayList适合随机访问和获取元素,而LinkedList适合插入、删除和遍历元素。
怎么声明字符串(String)?字符串new出来保存到哪里?如果是字符串常量保存在哪?
字符串可以通过直接赋值给变量来声明,例如String str = “Hello”;。字符串常量保存在字符串常量池中,而通过new操作创建的字符串对象保存在堆内存中。
StringBuffer和StringBuilder有什么区别?
StringBuffer和StringBuilder都是用来处理可变的字符串,但是StringBuffer是线程安全的,而StringBuilder是非线程安全的。在多线程环境下,如果需要对字符串进行修改操作,推荐使用StringBuffer,而在单线程环境下,使用StringBuilder可以获得更好的性能。
Java里除了Synconized,还有什么加锁方式?
除了synchronized关键字,Java中还有其他的加锁方式,如ReentrantLock、Lock接口、Atomic类等。这些机制可以更灵活地控制锁的获取和释放,并提供更多的功能。
介绍一下垃圾回收机制。
Java的垃圾回收机制是通过垃圾收集器来回收废弃对象所占用的内存空间。垃圾收集器会定期进行垃圾回收,找出不再被引用的对象,将它们所占用的内存空间释放出来,以供其他对象使用。
具体的垃圾回收器有哪些?
具体的垃圾回收器有很多种,例如串行垃圾回收器(Serial)、并行垃圾回收器(Parallel)、并发标记垃圾回收器(CMS)、G1垃圾回收器等。不同的垃圾回收器具有不同的特点和适用场景,可以根据具体的需求选择合适的垃圾回收器。
Flume的事务是怎样的?
Flume的事务是通过事务性存储器(TransactionChannel)实现的。当Flume接收到数据时,会将数据写入到事务内存中,并标记该事务为“正在进行中”,然后等待事务完成。一旦事务完成,数据会被提交到目标系统,如果事务失败,则数据会被回滚。
如何实现UDF?
UDF(User-Defined Function)是自定义函数,用于在SQL查询中扩展功能。可以通过继承现有的UDF类或实现UDF接口来实现UDF。实现UDF时,需要定义函数的输入和输出类型,然后实现对应的evaluate方法进行具体的逻辑处理。
UDF要成为永久函数怎么做?如果不加temperory,函数下次还能用吗?
要将UDF成为永久函数,需要使用CREATE FUNCTION语句将UDF注册到数据库中。如果不加temporary关键字创建函数,默认是永久函数,可以在下次会话中继续使用。
介绍一下UDTF?
UDTF(User-Defined Table Function)是自定义表函数,可以将一行输入转换为多行输出。UDTF需要实现TableFunction接口,并重写eval方法来处理输入数据。
Hive的窗口函数有了解过吗?
Hive的窗口函数是用于在分组数据上执行聚合操作的函数,可以通过OVER子句指定窗口的范围和排序方式。
开窗函数Over()中有没有orderby有什么区别?
开窗函数Over()中可以有orderby子句,用于指定窗口中数据的排序方式。如果没有指定orderby子句,则使用默认的排序方式,通常是按照输入数据的顺序进行排序。
Flink任务的并行度和内存怎么设置的?
Flink任务的并行度可以通过设置ExecutionConfig中的setParallelism()方法来进行设置,内存的分配可以在Flink的配置文件中进行设置。
Flink的TaskManager内存模型了解吗?
Flink的TaskManager内存模型包括堆内存、以及Off-heap和On-heap内存。堆内存主要用于存储数据和运行时信息,Off-heap内存用于存储Flink的元数据,On-heap内存用于执行堆外操作。
Flink 新旧版本之间的区别包括功能的增强、bug修复、性能优化等。
有没有了解过Flink的窗口函数?
Flink提供了丰富的窗口函数,如滚动窗口、滑动窗口、会话窗口等,可以根据具体的需求选择合适的窗口函数进行数据处理。
离线数仓做了什么工作?
离线数仓的工作包括数据抽取、数据清洗、数据转换、数据加载等。通过这些工作将原始数据转化成业务数据,供分析和决策使用。
数仓为什么要分层?
数仓要分层是为了更好地组织和管理数据。分层有助于提高查询和计算的效率,便于对不同层次的数据进行灵活的处理和管理,并能支撑多种分析场景。
实时数仓也要像离线数仓那样分层吗?
实时数仓也需要进行分层,但分层原则可能会有所不同,需要根据实时计算的要求进行设计。
开发数仓的过程中有哪些注意的点?优化的点?
在开发数仓的过程中,需要注意数据的准确性和一致性,保证数据质量;同时也要关注性能优化,如合理设置分区、选择合适的数据格式、合理设置压缩等。
拉链表的分区是怎么设置的?(一级分区、二级分区?)
拉链表的分区可以通过一级分区和二级分区来实现数据的分散存储。一级分区可以根据日期、地区等维度进行划分,二级分区可以根据具体的业务维度进行划分。
有哪些压缩方式?各有什么优缺点?
常见的压缩方式有Snappy、Gzip、LZO等。不同的压缩方式有不同的优缺点,如压缩比、压缩速度、解压速度等方面的差异。在选择压缩方式时需要根据具体的场景和需求进行评估和选择。
HDFS的小文件过多会导致什么问题?怎么解决?
HDFS的小文件过多会导致存储效率低下、元数据开销大和数据读写性能下降等问题。通过合并小文件、设置合适的块大小、使用SequenceFile等方式可以解决小文件问题。
MapReduce的原理:
MapReduce是一种分布式计算模型,包含两个阶段:Map和Reduce。Map阶段将输入数据拆分为若干片段并进行并行处理,生成一系列键值对。Reduce阶段对Map输出的键值对进行归并和聚合,最终得到最终的计算结果。MapReduce采用了数据本地性原则,借助分布式文件系统将数据移动到计算节点,减少数据的网络传输。
环形缓冲区为什么要反向?
环形缓冲区反向有助于减小跨页面访问的成本,提高数据访问的效率。由于CPU缓存的局部性原理,顺序访问的数据具有更高的缓存命中率,因此将数据反向存放可以增加数据的顺序性,提高缓存的效率。
Spark的原理:
Spark是一个快速而通用的集群计算系统,基于RDD(弹性分布式数据集)模型。Spark将计算任务划分为多个阶段,每个阶段包含若干个并行的任务。通过将计算过程中的数据保留在内存中,Spark能够实现较低的计算延迟和更高的吞吐量。Spark支持多种操作,如转换和动作,同时提供丰富的API和库,支持Scala、Java、Python和R等编程语言。
Spark、Flink的部署模式:
Spark和Flink都支持以下部署模式:
Standalone模式:在单机上运行Spark或Flink,方便开发和测试。
Local模式:在分布式环境中,将Spark或Flink的所有组件都运行在同一台机器上。
YARN模式:通过YARN资源管理器来分配和管理计算资源,支持任务的动态调度和资源隔离。
Mesos模式:通过Mesos资源管理器来分配和管理计算资源,也支持任务的动态调度和资源隔离。
YARN的角色和任务:
YARN(Yet Another Resource Negotiator)由以下角色组成:
ResourceManager:负责集群资源的分配和管理。
NodeManager:负责管理节点上的资源,包括任务的启动、监控和报告等。
ApplicationMaster:每个应用程序都有一个对应的ApplicationMaster,负责任务的协调和监管。
Container:YARN中的基本单位,用于封装资源(CPU、内存)和任务的运行环境。
YARN的调度器:
YARN支持多种调度器,包括:
CapacityScheduler:按照预定义的容量分配资源,支持多队列和资源配额功能。
FairScheduler:按照公平原则分配资源,每个应用程序都能获得公平的机会。
DominantResourceFairnessScheduler:基于优先级和资源需求的公平调度器。
Hive和HBase的区别:
Hive是一个建立在Hadoop上的数据仓库工具,提供类似于SQL的查询和数据分析能力。HBase是一个NoSQL数据库,基于Hadoop的HDFS存储数据。主要区别包括:
数据模型:Hive是基于关系型数据模型,支持复杂的查询和数据分析,HBase是基于列族的数据模型,类似于Bigtable。
查询语言:Hive使用类SQL语言(HiveQL)进行查询,HBase使用API操作数据。
存储方式:Hive将数据存储在HDFS上,HBase在HDFS上构建了一层支持随机读写的索引结构。
Kafka的作用:
Kafka是一个高吞吐量的分布式消息系统,用于发布和订阅流式数据。在大规模数据处理场景下,Kafka可以扮演消息中间件的角色,实现不同组件之间的解耦和连接。它支持持久化、容错、并行处理和可伸缩性等特性,适用于高吞吐量的实时数据流处理。
Kafka的架构:
Kafka的架构包括以下组件:
Producer:数据的发布者,将数据发送到Kafka的Topic中。
Consumer:数据的消费者,从Kafka的Topic中读取和处理数据。
Topic:数据发送和接收的通道,逻辑上相当于一个消息队列。
Partition:Topic的分区,用于实现数据的并行处理和存储。
Broker:Kafka集群中的一台服务器,负责存储和复制数据。
ZooKeeper:Kafka使用ZooKeeper来管理集群的配置和状态信息。
Kafka消息积压的解决方案:
处理Kafka消息积压可以从以下方面入手:
增加消费者的数量和并行度,提高消费速度。
调整Kafka的配置,增加分区数和副本数,提高吞吐量和容错性。
优化消费者的消费逻辑,减少消费逻辑的复杂度,提高处理效率。
监控Kafka集群和消费进度,及时发现问题并进行调整。
Hive数据倾斜的原因和优化:
Hive数据倾斜主要是由于数据分布不均匀导致的,可能是某个特定的键值或组合的数据量过大,导致计算任务不均衡。优化的方法包括:
调整分桶和分区策略,使得数据更加均匀地分布在各个桶和分区中。
使用随机前缀或哈希分区,将数据分散存储和计算。
使用扩展算子(例如LATERAL VIEW EXPLODE)对数据进行分拆,以减少特定键值或组合的数据量。
调整并行度,通过增加或减少Reducer数量来均衡计算任务。
小文件问题可以使用以下方法进行处理:
合并小文件:可以使用Hadoop的SequenceFile格式来合并小文件,将多个小文件写入一个SequenceFile中,减少文件数量。
使用CombineInputFormat:使用CombineInputFormat可以将多个小文件合并成一个输入切片,减少任务数量。
JVM重用:可以开启JVM重用机制,重用已经初始化的JVM来处理多个小文件,减少JVM启动和销毁的时间开销。
Hive支持的存储格式包括TextFile、SequenceFile、ORC和Parquet。
ORC和Parquet是两种优化的列式存储格式,它们的区别如下:
存储方式:ORC使用行组(Row Group)存储数据,每个行组包含多行数据,而Parquet使用列组(Column Chunk)存储数据,每个列组包含一个或多个列的数据。
压缩方式:ORC和Parquet都支持多种压缩方式,但ORC压缩率更高,适合存储超大表,而Parquet压缩速度更快,适合交互式查询。
数据编码:ORC使用了可变长度编码(Variable Length Encoding)和字典编码(Dictionary Encoding)来减小存储空间,而Parquet使用了位图编码和字典编码。
兼容性:ORC是Hive特有的存储格式,Parquet是一种开放的存储格式,被多个大数据处理框架支持,如Hive、Spark、Impala等。
常见的压缩格式包括gzip、bzip、snappy和lzo。
Hive的数据倾斜可以采取以下处理方法:
数据重分区:将倾斜的数据进行分区,将数据均匀分布到不同的分区中,避免数据倾斜。
使用随机前缀:对倾斜的键添加随机前缀,使倾斜的键均匀分布在不同的分区内。
聚合优化:对倾斜的数据进行预聚合,减少需要进行聚合操作的数据量。
键值对转化:将倾斜的数据转化为键值对进行处理,如将倾斜的join操作转化为map-side join。
动态调整资源:根据实际情况动态调整资源,如增加或减少任务的并行度,提高倾斜键的处理速度。
以上是处理Hive的数据倾斜的一些常见方法,具体的处理方式可以根据场景和需求进行选择。
分区和分桶的区别?
分区(Partition)是将数据按照某个特定的列分成多个不同的目录或文件存储,以便更高效地查询和管理数据。分桶(Bucket)是将数据按照哈希算法分成几个桶,每个桶中的数据大小可以不等,便于进行随机采样和均匀分布的操作。分区是根据列的值进行数据划分,而分桶是根据哈希算法对数据进行划分。
SQL提交到Hive的过程大致分为以下几个步骤:
解析器将SQL语句解析成抽象语法树(AST)。
语法分析器根据AST生成逻辑执行计划(Logical Plan)。
将逻辑执行计划转化为物理执行计划(Physical Plan),并进行优化。
生成MapReduce作业,将物理执行计划转化为一系列的MapReduce任务。
提交MapReduce作业到集群中执行,并等待作业完成。
Hive方面的调优手段有:
适当增加并行度和减少任务数量,以提高查询的执行效率。
使用合适的存储格式,如ORC或Parquet,以减小存储空间并提高查询性能。
合理定义分区和分桶,以避免全表扫描和提高查询速度。
使用合适的索引,如位图索引或Bloom过滤器,以减少数据的扫描和过滤。
使用动态分区插入和多行插入语句,以提高数据的导入速度。
使用Map-side Join进行连接操作,以避免大表和大表之间的内存溢出问题。
合理使用Join优化参数,如自动调整mapjoin的阈值等。
避免大表和大表之间的join内存溢出可以采用以下方法:
采用Map-side Join:如果其中一个表可以小到可以进入内存,可以将其作为小表进行Map-side Join,避免将所有数据加载到内存中。
调整Join操作的并行度:通过调整map端、reduce端并行度或启用合适的Join优化参数,可以减少内存消耗并提高Join操作的性能。
调整内存参数:增加Map和Reduce任务的内存限制,如mapreduce.map.memory.mb和mapreduce.reduce.memory.mb,可以为Join操作提供更多的内存资源。
全量数据是指每次处理时需要处理所有的数据,而增量数据是指只处理最新的变化数据。通常情况下,静态数据或周期性更新的数据可以采用全量方式处理,而实时变化的数据可以采用增量方式处理。为了实现全量和增量数据的处理,可以采取以下方法:
全量数据处理:每次处理时从源端获取全部数据,并进行数据清洗、转换和加载。
增量数据处理:根据数据的增量标识(如时间戳或增量ID),只获取最新的变化数据,并进行增量处理,如更新、插入等操作。
这样可以保证数据的一致性,并提高数据处理的效率。具体的处理方式可以根据需求和情况进行选择。
Flume挂了处理方式:
检查Flume的日志文件,查看错误信息,尝试找出导致Flume挂掉的原因,并做相应的修复措施。
重启Flume进程,如果是配置文件或参数问题,可以尝试调整配置文件并重新启动。
检查Flume的资源占用情况,如内存、磁盘等,如果资源吃紧可以尝试优化配置或增加资源。
如果以上方法都无法解决问题,可以考虑采取备份方案,使用备份节点继续接收和处理数据,同时对故障节点进行诊断和修复。
Flume实现精准一致性的方法:
启用事务机制:Flume可以通过启用事务机制来确保数据的精确一致性。在事务中,Flume会先将数据写入到临时存储(如内存或磁盘),等待事务完成后再将数据提交到目标存储(如HDFS、HBase等)。
配置可靠性机制:Flume提供了可靠性机制,可以配置数据重试、持久化和可靠性存储等功能,确保数据能够正确传输和存储。
监控和故障恢复:通过监控Flume的运行状态和日志信息,及时发现和修复数据传输故障,确保数据的精确一致性。
Flume写到HDFS的分区方式:
通过Flume的配置文件中的时间戳插件(TimestampInterceptor)来进行分区,可以将事件写入到不同的目录或文件中,以时间为维度进行分区。
自定义分区插件:可以开发自定义的Flume插件,根据业务需求对数据进行分区,如基于数据内容、关键字等进行分区。
Hive数据同步到HBase的方法:
使用HBase的Bulk Load功能:将Hive表数据导出为HFiles格式,然后使用HBase提供的Bulk Load功能将HFiles导入到HBase表中。
使用Hive的HBase Storage Handler:通过在Hive中创建外部表,并指定使用HBase Storage Handler存储格式,数据写入Hive表时会同时写入HBase表。
JVM的内存模型是指JVM对内存的组织和管理方式,主要包括以下部分:
栈内存(Stack):用于存储方法调用的局部变量和方法调用栈。
堆内存(Heap):用于存储对象实例和数组。
非堆内存(Non-Heap):包括永久代(Permanent Generation)和元数据区,用于存储类的元数据信息和常量池等。
方法区(Method Area):用于存储类的结构信息、静态变量和常量池等。
本地方法栈(Native Method Stack):用于存储本地方法调用的相关信息。
JVM的内存模型对依赖于Java运行环境的程序来说是透明的,但开发人员需要了解它的组成和特性,以便进行合理的内存管理和性能优化。
垃圾回收机制是指自动回收程序不再使用的内存资源的一种机制,它能够自动检测和释放不再使用的对象,以便回收内存空间。
常见的垃圾回收算法有:
标记-清除算法(Mark and Sweep)
复制算法(Copying)
标记-整理算法(Mark and Compact)
分代算法(Generational)
增量垃圾回收算法(Incremental)
内存碎片化指的是内存中存在一些零散的、不连续的空闲内存块。内存碎片化可能导致以下问题:
内存分配效率低下:在存在内存碎片的情况下,需要找到足够大的内存块进行分配,可能会浪费一些小的空闲块。
内存使用不连续:内存碎片化导致内存空闲块不连续,可能无法满足需要连续内存空间的操作。
常见的设计模式有:
单例模式(Singleton)
工厂模式(Factory)
观察者模式(Observer)
建造者模式(Builder)
适配器模式(Adapter)
策略模式(Strategy)
装饰器模式(Decorator)
模板方法模式(Template Method)
单例模式的实现方式有:
饿汉式(Eager Initialization)
在类加载时就创建实例,保证只有一个实例,并提供全局访问点。
懒汉式(Lazy Initialization)
在需要时才创建实例,延迟加载,并提供全局访问点。
双重检查锁(Double-Checked Locking)
结合了懒汉式和同步锁的方式,保证线程安全和延迟加载。
Spark程序的执行过程如下:
创建SparkContext:初始化Spark应用程序的环境。它负责和集群资源进行交互,并且是与Spark核心引擎进行通信的入口点。
创建RDD(弹性分布式数据集):通过读取外部数据源或对其他RDD进行转换来创建初始RDD。
执行转换操作:对RDD进行转换操作,如map、filter、reduce等,形成RDD的依赖关系图(DAG)。
触发动作操作:对RDD应用动作操作,如count、collect、save等,触发Spark作业的执行。
提交作业:将作业提交到集群,由Spark的调度器进行调度和分配资源;
任务划分:Spark将作业划分为不同的任务,并将这些任务分配到集群中的不同节点上并行执行。
任务执行:各个节点上的Executor执行任务,并将结果返回给驱动程序。
结果返回:驱动程序将各个节点上的任务执行结果进行汇总和整合,形成最终结果。
Stage是Spark作业中的一个阶段,它是根据作业的DAG图进行划分的。具体划分方式如下:
宽依赖划分:将作业DAG中存在Shuffle依赖的边界作为Stage划分的依据,即根据需要进行数据洗牌(Shuffle)的边界进行划分。
窄依赖划分:在宽依赖内部存在独立的任务链时,可能会将一个Stage再细分为多个子Stage,以提高执行并行度。
Shuffle是指Spark作业中进行数据重分区操作的过程,它主要涉及到数据的重新分组和排序。在执行Shuffle操作时,Spark会将执行节点的数据按照指定的Key进行重新分区,并将相同Key的数据打包并发送给同一个节点进行计算。Shuffle的过程开销较大,涉及数据的网络传输和磁盘IO等,因此需要在Spark程序中合理使用Shuffle,尽量减少Shuffle操作的频率和数据量,以提高程序的性能。
Spark和Flink是两种常见的大数据处理框架,它们有以下区别:
数据流模型:Spark采用的是批处理模型,将数据划分为离散的批次进行处理;而Flink采用的是流处理模型,能够实时处理无限流数据。
容错机制:Spark使用的是基于RDD(弹性分布式数据集)的容错机制,将数据从磁盘读取到内存进行计算,可通过重复执行容错的RDD操作来实现容错;而Flink使用的是基于状态的容错机制,通过定期对运算符的状态进行检查点(Checkpoint)来实现容错。
运行模式:Spark支持多种运行模式,如Standalone、YARN等;而Flink主要是在分布式环境下运行,如通过集群管理器如Apache Mesos、YARN、Kubernetes等。
数据一致性:Spark的批处理作业在随机抽样等场景下,存在数据一致性问题;而Flink的流处理模型具有事件时间和处理时间的一致性。
Flink的Checkpoint机制:
Flink的Checkpoint机制是一种容错机制,用于创建作业状态的一致性检查点。在执行过程中,Flink定期将作业的状态信息存储到持久化的存储介质中,以便在发生故障时进行恢复。Checkpoint包括作业状态的快照以及相关的元数据信息,如作业配置、操作符状态等。
Flink的Checkpoint机制的流程如下:
Flink生成一个Checkpoint ID,然后以该ID创建一个全局一致的快照。
Flink触发任务操作符进行快照操作,将操作符的状态和数据发送到持久化存储介质中。
一旦所有操作符完成快照,Flink会将快照的元数据保存到Checkpoint存储中,以便失败时进行恢复。
水位线是Flink用于处理事件时间的一种机制。水位线用于衡量事件时间进展,是一个时间戳的度量。Flink根据水位线确定触发窗口计算的时机,确保所有事件被正确地分配到正确的窗口中。水位线的更新策略可以通过编程方式进行自定义,常见的方式是基于事件时间的周期性更新,或者基于某个事件时间的最大延迟来更新。
对于迟到很久的数据,Flink可以使用侧输出流(Side Output)进行处理。侧输出流是指从主流中分流出来的一个或多个分支流,它可以用于处理迟到事件或异常情况。当一个事件的时间戳超出了某个窗口的结束时间时,Flink可以将这个事件发送到侧输出流,以单独进行处理,比如进行延迟计算、存储到外部系统等。
对于任务执行的流程,Spark的任务执行流程如下:
Spark应用程序启动并初始化相关配置和资源。
Spark将应用程序中的操作转化为一个个的DAG任务。
Spark将DAG任务划分为不同的Stage,根据Shuffle边界进行划分。
Spark将Stage中的任务分配给集群中的Executor进行并行执行。
Executor执行任务并将结果返回给Spark Driver。
Spark Driver整合各个Executor的结果并生成最终结果。
对于给定的1G文件,每一行一个词,词大小不超过16字节,内存大小为1M,要找出频数最高的100个词,可以使用以下算法:
将文件分成多个小文件,每个小文件可以全部读入内存。
遍历每个小文件,使用哈希表统计每个词出现的频数。
将每个小文件的哈希表合并到一个全局的哈希表中。
在全局哈希表中取出频数最高的100个词。可以使用堆排序等算法来实现。
输出结果即为频数最高的100个词。
有精准流量就有成交。
精准流量哪里来?
最简单的就是通过SEO来。
而且这种还是几乎完全免费的流量。
而且还是几乎源源不断每天每月每年都有的流量。
那么怎么学SEO呢?
不用报班,最好的SEO教程都免费公开了。
基础教程看下面两个:
谷歌SEO文档 https://developers.google.com/search/docs?hl=zh-cn
Ahrefs SEO 入门七篇 https://ahrefs.com/seo
之后进阶,可以看更多:
Ahrefs 博客: https://ahrefs.com/blog/
Semrush 博客: https://www.semrush.com/blog/
FirstPageSage 博客: https://firstpagesage.com/seo-blog/
搜索引擎行业资讯: https://searchengineland.com/
AI提示词
一套很容易出效果的人像,也可以用在占位图或者品牌宣传上。
需要更改的内容就是遮挡面部的物品,比如蝴蝶和花朵,还有就是整体的颜色氛围。
a close up of a young Chinese male covered in white and purple flowers, in the style of cyberpunk realism, charming realism, exaggerated facial features, high resolution, enchanted realism, pale palette –chaos 5 –ar 2:3 –style raw –v 6
🧪一套可爱 3D 小动物的提示词,比较简单改一下动物名称和颜色就行。#ai画图##晚安提示词#
提示词:
Tiny cute isometric cat plush emoji, soft smooth lighting, with soft pastel colors, 3d icon clay render, pink background –ar 9:16 –style raw
个人程序员开发软件
分三个阶段付30%,30%,30%,最后完工对方满意交付10%
例如雏形完成30%,中间修改30%,测试阶段30%,beta完成10%
给源码一个价钱,不给源码一个价钱,给源码等于软件卖了给他,他是所有者。
售后要给1-12个月的bug修复,自己决定
至于以后的软件更新也是自己决定,例如免费送三次,小更新就送,大更新就收费等等
好的帖子都是要酝酿的。
所以,趁着你有写作欲望的时候,多存几篇。
你不用全部发出来。
发一半你觉得还不错的。
剩下的一半,读起来“又酸又臭”的,丢到素材库里。
等待他们在里面“素材缸”里慢慢发酵。
后面很长一段日子里,你也许都不会想起它们。
直到你看到另一个话题/选题,突然想起自己还藏了一些东西。
你再把它们从缸里捞出来。
两个搭配在一起,翻炒一下,有时会是用户非常喜欢的一道“内容创意菜”
#内幕消息
4 个关于开店选址的准则:
1、人流量不等于客流量。
重点是分析方圆500米、1公里、3公里的核心客群。
2、要不要选择进入新城区?
答案是可预期的增长下,入住率在25%-40%是最佳的进驻时机。
3、如何判断商圈的家庭结构?
幼儿园、麻将馆、十元快剪代表了不同的人群特征,亮灯时间是重要指标,极简模型:天黑就亮是家庭,9点才亮是情侣单身,清晨亮灯老年人。
4、选不到小区门口,什么位置还可以选?
答案是核心人群的路线交点。买菜、接孩子、广场舞…相交的地方就是你要的位置。
来自黄碧云的分享。
#阿机的信息差
#内幕消息
《经济下行期,“义乌式”跨境电商是谁的机会》
回义乌一年多,恰逢全球经济下行,义乌赚钱却如火如荼,一年内见证了身边无数个草根年赚百万/千万的案例。误打误撞置身其中,自己也起了个跨境电商项目,记录一些思考。
🍃首先,定义下我说的“义乌式”跨境电商。
区别于广深,我理解中的义乌式跨境电商特点:投资少门槛低、利润低、多平台游走。
和广深跨境卖家不同,义乌是草根创业的胜地,因为义乌创业成本低,几万、几十万就能开启自己的创业梦。加上义乌的基因:低价货盘优势明显、创新/内容能力薄弱,卖家基本都是薄利多销。哪怕是to C卖家,很多人仍是跑量思路。以上特点导致义乌商家壁垒低、抗风险能力弱,所以不少义乌跨境中大型卖家选择同时做好几个跨境平台,分散风险。
🍃其次,义乌式跨境电商是谁的机会。
我这一年见到的中大型跨境卖家,听说我是留学生、大厂工作背景,第一反应都是:你这样的背景来做跨境真的屈才了。
他们的背景,大学毕业算是很不错的了,也有好些是大专甚至高中毕业。年纪的话,早一些的那批大多90上下,新生代大多95-00年,公司20来个人,年GMV从几千万到几亿不等。
但做了一年后,我发现我的背景恰恰变成自己做跨境的最大门槛。跨境电商难度不大,但是里面有非常多细碎的环节,比如这个品平台质检出问题、那个品贴标不对,这个货快递发货延误、那个货货不对版,每天接不完的仓库、快递、厂家电话,就能让我失去耐心无数次。
我和那些今年成长起来的大卖之间的差距be like:
我:没有30%的纯利我不做,销量低没事,但我要保证赚的多。
大卖:10%的纯利?冲。跑量最重要,跑量后反向去上游压缩成本。
我:几毛钱的品?每天还贴标还发货,性价比太低,砍掉。
大卖:几毛钱的品可以跑量,做。
总之,遇到太多,在我这第一眼就会被pass掉不想做的品、不想做的平台,但是在大卖那儿成长为他们盈利核心点。
愈发感觉,跨境的人才密度是不高的,但是所谓的高学历、高认知的人入局,也不见得就是降维打击。有太多不重合的能力项。
但是在义乌,真的“知识无用”吗,我觉得也不尽然。
和这些卖家接触下来,他们做到每年大几百甚至一两千万的体量可能难度不是很大,但是再做大,就会遇到组织管理、人才的选用育留、公司增长方向判断、增长能力等问题。
这也是为什么,和广深闽比,义乌少有超大体量的跨境电商公司。
有些老板愿意花几万去学线下的组织管理的课,有的老板愿意花100万请咨询公司来给公司把脉,但是咨询公司给的解决方案大多和义乌偏野生的公司形态并不适配。
在这个阶段,对于在大公司上过班、管过100多人团队的人来说,以自己的管理能力、业务洞察和提效能力赋能,可以很好地帮助公司快速上一个台阶,这时候积累下来的护城河,就不是其他的义乌公司能比的。
在义乌摸爬滚打的这一年,对自己的能力象限,尤其是自己的局限性有了更加深刻的认识。如何结合环境的需求和自己的优势,探索出自身资源最大化的路径,是下一个核心课题。
有幸听某位市长讲了下房地产的一些逻辑,趁着脑子还清醒,赶紧记录下:
为什么要房住不炒?
因为发生了结构性改变,下文会详聊
房地产怎么发展起来的?
1980年,城市居民1.8亿,人均住房5平方
2020年,城市居民9亿,人均住房50平方
80年的时候,人多地少,需要解决住房,拉动内需,拉动经济的目标,而房地产可以满足,小平改革开放使得城市机制得以释放:
城市机制释放农村篇:
1 承包制,使得5亿种地农民降到只需要2亿,剩下3亿可以出去打工,带来了第一波城市务工人群
2 进城工作,以前的户籍制度是不能让农村人口进城务工的,更改以后人口流动增加
3 打工到一定年限以后,可以获得城市户口,从而从农村人民转化成城市人口
城市机制释放城市篇:
1 土地批租制度出现,导致出现房地产商
2 产权房出现,92年以后,出现产权房而不再是公有制房屋,以前的公有制可以转化成私有制
3 按揭贷款出现,可以拉动杠杆,让居民大额消费出现
4 城市投融资平台出现,使得效率提高
5 城市成立开发区,以单独区域形成城市新发展极,拉动城市化率
这些举措使得城市化率迅速飙升,也造成了中国快速发展的几十年,当然,也导致了房地产商大规模举债,拉杠杆拿地,开发,预售,银行放贷,使得快速发展,也埋下一定隐患
而当前具体指标出现了拐点,使得房地产从白银时代变成了黑铁时代,结构性改变
1 人口下降,需求开始下降,不会有以前那种越来越多的人买房了
2 城市化率65%,基本封顶,欧美基本上也就是75%左右,而我们的城市化里,有一部分是吸纳农村的劳动力,所以相对偏低(即,农村户口实际上在城市长期生活)
3 老龄化加速,老年人对房屋需求不如年轻人强烈,死亡率上升导致房地产空置率提高
4 存量房库存(新开发1年以上卖不动)有6亿平(注意,不是烂尾),90年以后新建房400亿平,其中300亿在居民手里,居民手里闲置投资房占比20%,也就是60亿平闲置,此前年涨幅20%,闲置会划算,但是房子不涨以后,闲置就会流动,从而稀释交易需求
5 人均住房面积到天花板,人均50平,已经媲美发达国家(也是人均50)
6 建设量封顶,此前90年1年1000万平米新建设,00年1亿平,10年10亿平,17年17亿平,而同年全世界新建居民房屋37亿平,中国占比接近一半,而人口占比并没有接近一半,显然过剩
7 城市大规模基础性建设(路,医院,学校等)基本封顶,提升空间没那么大
8 房地产商金融负债率90%,而香港40%,欧美50%,政府给的70%红线,仍然有很多企业没达到
而房地产会不会雪崩?
不会,会想尽一切办法使其软着陆,因为房地产占比我们的GDP10个点,如果没搞好负增长了,那就是极大不稳定,所以会限制新房建设,保障存量交付
房价会不会继续涨?
不一定,北上广深等人口涌入的地方,仍然是人口流入有需求,可能会涨,但是也不会疯狂了,因为流动性变稀释了,而人口流出的城市,尽可能在租售比离谱之前跑掉,是安全的做法
大佬年赚100w的榠型
按照这套横型走,一年100万问题不大。
第1步:卖
先确定好要卖什么。
接地气的赚钱模式,就三种。
1、卖实体。比如二手手机、IPAD、燕窝、海参、水晶等优先选择高利润、高复购产品。
2、卖资料。比如教资资料、公考资料、恋爱资料考研资料、会计资料等等。
3、卖服务。比如情感咨询、心理咨询、创业指导挽回、律师咨询等等。
第2步:寻找同行
寻找50个优质同行
某音、某书某乎、某号等平台,筛选出50个优质同行。
建立EXCEL文件,做同行数据库,标明他们的平台主页链接、粉丝数、选题、更新频率。时刻关注新冒出的同行,填充到自己同行数据库。
第3步:模仿和学习
学习他们的内容形式、选题、文案结构、更新频率等等。然后采集内容,做内容素材库,自己模
份生成。内容生产流程要拆成各个环节:环节ABCDE..
每个环节批量去做,比如文案就批量做 50个,剪视频就批量剪 50个。
一个环节批量做,是为了减少不同环节切换造成的损坏,同时重复性动作批量做可以滅少时问。
第4步:批量分发
每天产出 50个视频/图集,准备5个手机。瞄淮10个分发平台:某书某音、某手、某乎某条、某号等等,然后批量分发。
1个视频发1个平台,就是一个触点。
550个视频分发10个平台,就是500个触点。一个月就是15000个触点,一个触点,搞来一个
精淮流量,也值了。
第5步:成交转化简化成交,用某信就行。
#内幕消息
偶然刷到小宇宙 @kyth 的动态,刚好有些相关的了解来写条分享
大多数人消费内容时,会在意内容的生产成本高低吗?
https://m.okjike.com/originalPosts/65cf33aede5f287348684fcb
我觉得这是个好问题,让我想到了一个高度匹配这个描述的创作者:MrBeast
如果要说有谁最擅用生产成本增加内容吸引力,MrBeast 不算第一也肯定能排进前列。
在学习内容创作的时期,我曾经在一档专注讨论创作者经验的播客 Creator Science 中听过对 MrBeast 的分析 [1]。
这一期的嘉宾 Phill Agnew 花了 50 个小时专门分析 MrBeast 的频道,自己也是另一档播客 The Nudge 的主播,他的播客则是专注于分析营销背后的行为科学的。
他们当时聊到了 MrBeast 在视频为了增加吸引力中用到的 3 个心理学理论:
- 投入偏倚(input bias)
- 昂贵信号理论(costly signaling)
- 对比效应(contrast effect)
而这里面的前两者,刚好对应了 kyth 问的问题「大多数人的内容消费,是否会关注内容生产成本」。
- 投入偏倚(input bias)
当我们了解到某事或某物背后的投入很高,我们会更倾向于高估它的价值,比如一瓶几十块的酒,对比几百块的酒。
这里的投入是广义的,可以是时间、也可以是金钱,或是其他能体现出费时费力的指标。
播客里的例子提到了一个围绕搜索等待的实验,同样是搜索航班信息,一组只显示转圈加载,另一组展示搜索的细节过程(具体展示搜到的每家航司信息、每步动作),让用户为体验评分,结果后者更高。
这也让我想到加载等待的设计,相比于常规的播放循环动画,用一些方式展示过程的投入可能会更有益于提升用户/玩家体验,比如产品设计中 Arc Search 的 Browse for me 会展示搜索找到的每个信源和当前生成阶段,Notion Q&A 中会展示 AI 当前的动作、正在阅读哪一篇笔记;游戏中《饥荒》生成地图的文案、《动森》好友联机的航班包装。
如果观察下 MrBeast 的视频标题和封面图,你会发现强调投入成本的这一做法几乎无处不在。
Pill 自己用广告投放做了个实验,同样的内容,强调生产的投入时间相比不提及生产投入,点击率提升了 45%。
类似的现象在国内也有观察到,比如 B 站盛行的《耗时xx小时,xxx》,真的是太常见了,这类标题能广泛扩散,不太可能只是单纯的模仿。
这也让我想到个有趣的事情,之前 AI 刚火起来那会,不少人觉得 AI 生成的东西很廉价,包括更早的时候咖啡行业出现机器人手冲、消费者觉得没有灵魂。我猜可能也有投入偏倚的影响在,因为都是把需要大量人力投入的事情变得唾手可得,时间消耗显著减少了。
- 昂贵信号理论(costly signaling)
指我们在传达信息上花费的金钱越多,人们越会注意我们所传达的,这和前一个理论有重合(比如讨论的都是金钱时),但不完全等同。
MrBeast 可以算是这方面的典型案例了,他在制作视频时出手非常阔绰,动不动就花费重金,这也是他的内容为什么能这么吸引人。
为了验证昂贵信号理论,嘉宾 Phill 围绕他自己的播客 The Nudge 做了一场实验,用两种方式做推广,使用同样的素材,但有一种是通过广告牌展示,广告内容主要是说服人们 The Nudge 为什么值得一听。
实验结果来看,看过广告牌版本的相比普通广告的,人们愿意听播客的可能性高了一倍。
我觉得这也可以延伸讨论到另一个有趣的现象,AIGC 火热之际,「积极拥抱」AI 生成内容的厂商被玩家抵制。
虽然识别 AI 生成的美术资产有门槛、需要对美术和这类 AI 工具有一定的了解,但并不影响玩家们得知 AI 技术运用后觉得游戏内容廉价,机核谈 AI 的一期播客也有过这个观点 [2]。
AIGC 在游戏行业的推行,主打一个降本增效,常识中也会倾向于认为 AI 的使用比人力便宜,按照昂贵信号理论,会觉得廉价也是理所当然。
从这个角度来看,对于 AIGC 的采用,厂商最好不要向玩家大肆宣传,我觉得这个很像预制菜,有多人会因为餐厅使用预制菜而有更高的消费意愿?
除了上面讨论的这些,昂贵信号理论的成本也可以是机会成本。
这里提到了两个例子,一个是 Jay 的付费社群,另一个是鞋子的品牌 Patagonia。
作为内容创作者,Jay 有一个专门用于交流学习的付费社群,但这个社群并不是谁都可以进,人数是有上限的。Jay 设置了一个两百人的上限,再多就要排队等待了,就算有钱也进不了。
而卖鞋的 Patagonia 也类似,并不是谁都可以买他们品牌的鞋,如果消费者是某家破坏环境的企业的员工,Patagonia 并不会把鞋卖给他们。
这种自我加限制的行为看上去很傻,但提高机会成本,也是为了更好的保证结果的价值。Jay 是为了更好的社群环境,Patagonia 则是为了践行自己对环保的贡献。
类似的例子我去年也遇到了一个,TEDx 的报名,不像常规活动花钱买票就能参加,有一期我注意到,买票前要填写不少信息、经审核通过后才有购票资格。
看似繁重的审核流程,显得活动的参与机会更加可贵,也让我对届时能收获的价值更抱期待了。
参考来源
[1] Phill Agnew 谈 MrBeast 在内容创作中用到的 3 个心理学理论 https://share.snipd.com/episode/d7cfc2ea-41da-45f9-981d-80419192f5e1
[2] 机核播客谈游戏开发与 AI 如何共处 https://www.gcores.com/radios/165043
#内幕消息
查查你有没有漏掉的小钱钱
#查查你有没有漏掉的小钱钱。
很多App都具备了一站式查询的功能,帮助理清所有的账户、保单,我整理了下。
#1 存款:「云闪付」app
「云闪付」app首页有「一键查卡」功能,可以查看本人名下所有的银行账户,方便统一进行银行卡的管理。
#2 股票:「中国结算」app
「中国结算」app首页「一码通资产查询」功能,可以查看本人名下所有A股券商账户,有哪些ETF、股票、可转债,有多少钱。
#3 保险:「金事通」app
「金事通」app首页有「人身险」「车险」「投资型保险」等功能,可以查看本人名下所有保单,还有待续费的提醒,方便做好个人和家庭的保单整理。
#4 基金:「基金E账户」app
「基金E账户」app首页有「公募基金查询」功能,可以一站式查询购买过的基金。
#5 电话卡 :「一证通查」微信小程序
在微信搜索「一证通查」选择国家政务服务平台下「电话卡一证通查」,填写姓名、身份证号、手机号,就可以查询到在各个运营商下有多少电话卡,方便自己管理的同时,也规避诈骗或被利用的风险。
#内幕消息
#一年一次的退税红包怎么领?两招教你由补缴变退税
一年一度的个税申报,又来了。
很多朋友可以领国家发的“退税红包”的,却因为操作不当,需要补税。
发下我以前写的文章,介绍两个退税小技巧,可以多领些红包。
内容包括:什么是个税申报,如何办理,两个退税小技巧,商业保险如何抵扣个税。
*什么是个税申报
平时我们的扣缴义务人(一般是所在的公司),依税法按月帮我们缴税;
等过完这一年,我们再回头合计下这一年,多交钱还是少交钱了:
国家按年来合并计算工资薪酬、劳务报酬、稿酬和特许权使用费等4类收入,再按照相应的税率来扣税。
如果多交了,那就国家欠咱们钱,可以申请退税,拿到“红包”,常见这几种情况:
(1)假设2020年年度,乔木的综合总收入不超过6万元,但是查询后,却有预缴过个税的记录,那么我就可以申请退税,美滋滋的拿到一笔钱。
(2)2020年月薪有变化,上半年收入较高,下半年公司业绩低迷,收入骤减甚至失业了,那么预缴税款和应交缴金额会存在偏差,也有机会拿回多缴的钱。
除了个人收入的变化之外,还有这些情况也会导致预缴税款大于应交税款,也可以拿回一些钱,即充分利用专项扣除:
(1)比如2020年,配偶或者孩子不幸生了大病,有一大笔治疗费用开支;
(2)孩子去年开始上学,包括幼儿园,或者在外工作有租房、自己买房有房贷以及家里老人达到了赡养的年龄(年满60周岁)等;
(3)2020年我们国家受到疫情影响,尽自己的能力捐赠等。
如果少交了,那就根据实际少缴的金额来进行补缴,需要咱们自觉给国家补上,常见这几种情况:
(1)自己上半年的收入较低,下半年得到晋升或者完成项目涨薪啦,咻的一下拿到更多月薪,那么大概率是需要补缴税款的。
(2)又或者除了本职工作收入外,还在业余时间画画、写文章投稿等,总收入高于预扣税率,也是要补缴的哈!
如果提醒你补缴的话,科普一个省钱小技巧:
当这笔钱不超过400块,或者咱们去年的收入没有超过12万,就不需要补缴啦。
所以即使年收入小于12万,也建议做下个税申报,可能也有退税惊喜。
年收入12万的同学,就按规定主动申报啦,如果当做不知道,有可能会影响个人征信的。
*如何办理个税的年度汇算
官方介绍的办理方式有三种:自己动手、请公司/单位办理、委托专业的服务机构。
作为新时代青年,建议大家自己办理!在应用商店或者APP Store直接搜索“个人所得税”,下载安装并注册即可。
进入到应用页面后,可以通过这三种简单的方式进入年度汇算确认界面:
(1)点击左上角:我要办税——选择需要的项目——比如综合年度所得汇算;
(2)点击首页页面中间的年度汇算——开始申报——选择年度信息。
(3)首页界面下拉找到常用业务——4项业务中选择自己需要的——比如综合所得年度汇算——选择2020年。
在这里以第一种方式为例,步骤如下:
我要办税——综合个人所得年度汇算——选择申报年度2020年——阅读并知晓提示——填写工作单位。
最后提交退税申请——填写银行卡信息——等待税务审核——国库处理——查询到账,就完成了。
*两个退税小技巧
个税申报其实不太复杂,大家动动手都是可以搞定的,不过还是有些操作技巧的:
第一招,用好专项附加扣除:
(1)子女教育:纳税人的子女接受学前教育和学历教育的相关支出,按照每个子女2000/月的标准定额扣除。
(2)继续教育:纳税人接受学历,在规定期间可按每月400元定额扣除,非学历继续教育的支出,可以按3600元定额扣除。
(3)大病医疗:纳税人在一个纳税年度内发生的自负医药费用超过1.5万元部分,可在每年8万元限额内据实扣除。
教你个简单的办法,下载国家医保服务平台app,人脸识别后直接看到自己符合“大病医疗”可以抵扣个税的金额。
(4)住房贷款利息:纳税人本人或配偶发生的首套住房贷款利息支出,可按每月1000元标准定额扣除。
(5)住房租金:纳税人本人及配偶在纳税人的主要工作城市没有住房,可根据承租住房所在城市的不同,按每月800元到1500元定额扣除。
注意房贷和租金这两项只能申报其中一项。
在北上广深这类一线城市,其实租房可以扣除的税额比房贷可以更高,算是帮大城市打拼的年轻人们省点钱。
(6)赡养老人:纳税人赡养60岁(含)以上父母的,按照每月3000元标准定额扣除。
第二招,用好计税方式:
一次性奖金收入,通常是年终奖,我们可以在收入栏里面选择工资薪金:
点进去选择奖金的计税方式,看看单独还是并入,哪种计税方式对我们最划算。
*商业保险如何抵扣个税
我们平常买的商业健康险,包括寿险、重疾险、医疗险等,通常不能抵税。
可以抵税的商业险有三种:
(1)企业年金
这个是公司或单位给的补充养老福利,个人在市面上买不到。
(2)特定的税优健康险
产品模式为1年期的医疗险+万能险,但必须要有专门的税优识别码才可以抵扣,最高上限是每年2400元。
而且产品刚出来没几年,目前太小众,还有保额低、报销比例低等很多局限性,保险公司没有很大动力去推,导致我们可以购买的渠道也很少;
一般需要通过团体投保,也就是企业来主导,需要企业上传营业执照、财务统一报税之类的,比较麻烦。
希望税优健康险以及企业年金、职业年金在未来几年会逐渐形成主流形式,到时我也会积极科普给大家的。
(3)税收递延型个人养老保险
简单来说就是把现在用来交税的钱,拿来买养老保险,退休后领钱的时候再交税。
每年限额12000元,根据不同的税率,个人养老金部分最多能退5400元。
*写在最后
无论是补税还是退税,希望大家都能更端正地看待报税这个问题:
减税是还利于民的整体大趋势,而且正是我们纳的税,为夜归人多点亮了几盏路灯、让山区的孩子多了新的文具和书本……
甚至“胖五”飞天、辽宁舰下海,背后都有我们汇聚的点点滴滴的力量。
被你改变的那部分我,代替你留在我身边。
#AI绘画
忍不住再推荐一次 Layer Diffusion,直接生成 PNG 素材真的对设计师太太太友好了~~~~~甚至能直接生成发丝和透明玻璃杯!
这工作流兼容 SDXL 系列的所有模型和 Lora,我用的模型是 DreamshaperXL Turbo,4~8步就能生成效果很好的素材,直接把生成速度压缩到秒级,见图1。
▶ 插件安装和部署:https://github.com/huchenlei/ComfyUI-layerdiffusion
▶ DreamShaper XL 下载:https://civitai.com/models/112902/dreamshaper-xl
最近和@海辛Hyacinth 做的鸡尾酒单就是用它来加的装饰素材(https://m.okjike.com/originalPosts/65e34fee38849f879fc12483?s=ewoidSI6ICI2MzkwNTUwZTljMzFjOGZjMWM3NzIyMzIiCn0=)
☁️
你甚至可以把整个流程反过来 —— 给现成的 PNG 素材生成背景,工作流见图7。 这简直是所有产品展示场景的刚需!
☁️
最后补充一个冷知识:Layer Diffusion 的作者之一就是 Controlnet 的作者 Lvmin Zhang~!
谢谢,不愧是你!
发现了一个小众应用,用 instant-id + logo lora 给自己做产品 logo!成为下一个老干妈!
今天,有个对AI特别感兴趣的朋友问我:“作为一个没有技术背景的人,想要深入探索AI,应该从哪里开始?
是不是应该先学习一些基础知识,比如Python编程和AI的基本概念,这样在未来理解代码、部署AI技术时,更加得心应手?”
我当场就急了,赶紧回复他说,晚点要专门写个帖子,回复这个问题。
1、
开宗明义:对于没有技术背景的小白,虽说迟早会学一点技术上的东西,但千万不要一上来就学技术。
本来就没啥技术底子,根本啃不动。别到最后,技术没学成,对 AI 的兴趣也荡然无存了。
如果本身就是某个领域的专业人员,还要去从零开始学技术,完全是舍近求远。
因为在AI市场上,缺的不是学了点基础 Python 的入门级工程师,而是懂某个领域 know-how 的行业专家。
2、
所以,更正确的路子应该是什么呢?从个人探索的角度,我总结了4个原则:
①Monkey First
“Monkey First”是Google X部门的一个口头禅,其含义是在解决问题时应该首先关注最困难的部分。
具体来讲,如果你的任务是让一只猴子站在基座上背诵莎士比亚的作品,”Monkey First”的策略会建议你应该将时间和资源集中在训练猴子上,而不是建造基座。
这是因为,基座的建造虽然看起来是在取得进展,但它并不会帮助你解决最关键的问题:如何让猴子背诵作品。
回到用 AI 上,对于非技术人员而言,最关键的问题绝不是花里胡哨的AI小技巧,而应该是如何借助AI提升我们的核心竞争力。
②生意为先
当然,许多人可能并不清楚,自己的核心竞争力在哪里。如果是这样的话,不妨考虑如何利用AI帮助我们更有效、更持续地盈利。
比如,从我们最熟悉的业务入手,思考它的关键要素有哪些,哪些方面是你最擅长的。明确了这些之后,再思考如何使用AI来进一步扩大这些优势。
反之,如果连基本的生意逻辑都搞清楚,盲目去探索 AI 所谓的可能性。很有可能会忙了半天,却一无所获,瞎子点灯白费蜡。
③精益创业
别看短视频天天吹,AI 替代某个工种、颠覆某个行业。真到了实干的环节,最牛的 AI,也不过名校实习生水平。它只能一点一点地干,一不小心还也可能出错,远没到可以独当一面的程度。
所以,在我们最熟悉的业务上,AI 到底能干成哪样,压根没人知道。我们只能原子级地一点点地尝试,测试多次到确认可行后,再进到下一个阶段。
这里还有个小的 tips,在原子级尝试的过程中,尽可能使用最强的AI。因为市面上有太多打着 AI 旗号的垃圾产品,看似免费或低成本,实际上却解决不了任何问题,看他们一眼都浪费时间。
以上的这些过程,就像互联网时代的“精益创业”,先用最小可行产品(MVP)把事情跑通,再去不断迭代和放大。
④思考框架
当原子级的尝试成功后,接下来就可以考虑系统性地解决问题了。
如果已经有成熟的SOP,那就尝试把某个环节的 SOP,做成一套提示词。然后,不断调整这套提示词,直到它可能稳定输出满意的内容为止。
如果没有成熟的SOP,那就尝试找一下解决这类问题的思考框架。这套框架可能来自书籍、课程,甚至可能来自某篇博客、公众号文章。然后,也可以像转化 SOP 一样,把这套思考框架变成提示词。
3、
拆解下来确实挺简单的,但往往越简单越有力量。
比方说,在我个人学习方面,目前也才到了这一步。
可在去年的这个时候,我还是完完全全的 AI 门外汉。
坚持这4个原则不到一年,我居然也在某个细分领域做到了“行业领先”,还有多家出版社跑过来找我出书……
Cloudflare白嫖党又来了,分享几个基于workers的项目,免费,抗DDOS,每天10W次免费请求,个人出海非常够用!
ps:我的某个网站就是部署在这上面hhhh
1️⃣ 博客
✅ 利用 worker 的 KV 作为数据库搭建博客
https://github.com/gdtool/cloudflare-workers-blog
✅ 利用 workers+github 搭建博客系统
https://github.com/kasuganosoras/cloudflare-worker-blog
2️⃣ 导航站
https://github.com/sleepwood/CF-Worker-Dir
3️⃣ 图床
https://github.com/iiop123/workers-image-hosting
4️⃣ 短网址服务
https://github.com/igengdu/short/
https://github.com/crazypeace/Url-Shorten-Worker
https://github.com/Closty/duanwangzhi
独立开发4年,分享几点最近的思考:
一定要给自己时间定价,哪怕没有人认可也要,这是对自己时间注意力保护,远离白嫖,伸手党。
开始做自己的小生意,带个货,建一个群?哪怕收费 9.9元,也是不错的开始,认知到这点很重要。
1元的小生意,放大千倍万倍收益也会非常客观,最近认识的朋友无一不是这样,批量操作几百个GZ号,VX号等等
独立开发者容易上手的小生意:1. 小工具 ,2. 做社群,3. 做课 4. X 推广广告(如果你有读者)
CSDN副业最近不错:1. 赚取平台资料源码收益 2. 私下部署,接单毕业设计等项目
让别人知道你是谁?你能干什么?能提供什么服务很重要。
你刚开始做什么不重要,重要的是你多年以后依然在做这件事,就能拿到自己的红利。
先动起来,而不是等想清楚,很多事情干起来才会更清楚。
提高效率方法:缩短路径,降低损耗,如无必要,勿增实体。
10 、所有生意在AI加持下都值得重做一遍,AI衍生出的闲鱼代写,AI绘画,都是类似的小生意,尤其公众号AI爆文,很值得关注,
11、学会表达自己很重要,这是个表达者红利的时代,不一定非要社交平台,在朋友圈分享也是一个方式。
12、 利用好工具,做一些自动化,比如RPA,爬虫,这是技术人核心优势。
小红书引流私域,没有绝对安全的方法,只有暂时可能比较安全的技巧。
以下是9个方法:
1、私信。
直接私信回复微信号。(数量达到一定就有高风险)
2、群聊。
用小号在群聊里回复微信号,或图片上放大才能看到的微信号。
3、置顶笔记。
置顶笔记里放一张图片,放大后才能看到微信号,或置顶笔记评论区写微信号。
4、账号简介。
小红书号先修改成微信号。其次,简介上用🛰️代指微信,留下微信号。
5、小号。
在首页简介@小号,并在小号简介、置顶、评论等留好微信号。
6、评论区引流。
用第三个号在评论区“求分享”、“怎么联系”,然后再评论区回复@小号。或置顶小号的评论。
7、店铺引流。
上架一个1 元单品,设置一个发货内容,备注“记得添加作者微信”。
8、互动组件。
在最新的各种互动组件中留下微信号。
9、聚光平台。
这是目前大量引流私域最稳定的方法,最低 2000 充值,日均最低消费 50-100 元。
投放三天后自动获得私信豁免权。
小红书引流私域,你还有什么方法?
讲个程序员恐怖故事:你混淆过的JS代码将和“开源代码”没什么区别。
不信的话可以试试这prompt:“分析这段代码是在做什么?然后翻译整段代码使其成为更加易懂的JS,把所有变量和函数都重命名”,然后你就会看到ChatGPT把你混淆后的代码还原。
Web App、Chrome插件、Electron软件危
昨天答应的 ComfyUI 人像发色更换保姆级教程视频来了。#ai# #教程# #comfyui#
我会先大概讲一下原理,然后再讲对应节点的作用和参数。最后会发散一下其他的方式,比如更换美瞳以及换衣服。
工作流原理:
主要用到了 SD 中局部重绘的原理,关键在于如何选中我们需要选中的区域,这里的突破主要是 Yolo World 这图像分割项目以及 ZHO 的 Comfyui 节点。
这个项目可以精准的识别和分割人物的不同区域的位置,我们根据不同区域的组合就可以选到需要的区域去重绘。
节点作用及参数:
YoloWorld Model Loader 和 ESAM Model Loader:加载模型用的用默认设置就行。
YoloWorld ESAM:输入框输入需要分割区域的单词,Confidence_threshold 需要分割的区域越精细数值越小,反之越大。
遮罩相减:取两个链接遮罩的交集。
遮罩扩展:扩大遮罩选取范围,倒角是让选区更加平滑。
采样器:降噪幅度,修改的内容与原图越不同重绘幅度需要越大。
一份送给刚入职新公司、试图在最短时间熟悉环境、变成业务老炮儿的,业务上手SOP:
1️⃣ 明确部门分工
先认清自家地盘,了解部门架构,谁负责哪块,协作团队有哪些。这就像打开游戏地图,先看清全局,后续探索才不迷路。有了对架构的了解,后面看群聊里面的记录,看文档的撰写人,也知道他们的立场和出发点,事半功倍。
2️⃣ 明确涉及产品
我喜欢看的见的东西,一定要有一个抓手切入,最简单的就是你的运营是怎么工作的,他们用什么平台,从运营视角进行操作熟悉,体验一轮下来就大查不查知道这是什么事儿了。有个要注意的点,最开始接触平台一定很心乱,很多模块和功能,也不懂哪些用或不用。还是建议先建立大的认知,知道这个平台整体是干嘛的,里面的功能分类有哪几块,运营用的是什么,先熟悉这块。这个后面单独再发个小红书!
3️⃣ 周报里的线索
查看部门周报,关注核心/最近需求:周报是个好东西,虽然平时不愿意写,但写出来就是宝,难怪领导爱看。周报基本上是一周下来,你们部门或者组里最重要的事儿,最核心的关注点。用这些具体的事儿作为切入点,对业务就好理解了。
4️⃣ 输出总结文档
输出倒逼输入,自己把框架列出来,完形填空填内容,不懂的东西或者问或者找。最重要的可以把东西落实下来,不会有错觉“好想学到了很多,好像又没有”。
5️⃣ 词汇扫盲,黑话修炼
回头对平台、周报、PRD、会议上面的词汇进行扫盲,查漏补缺,看看哪些部分还没理解,逐渐适应新公司新部门的语言环境。
6️⃣ 业务规划,保持思考
来了还是要干活的,可以先看看部门或者业务整体的年度计划,最后基于以上先给自己一个大概的规划,自己要干的是哪些事儿,这些事儿后面可能是什么方向,然后和老板在聊一下想法,完美,还凸显自己有思考hhh。
干就完事儿了,升职加薪不好说,一顿表扬怎么也是有的。
白牙入职腾讯三周年时,写了一篇文章,简单分享下这一年,白牙都学到了什么。
01-认知提升
1.成长是件很私人的事,成长是你自己的事,你需要100%负责。
2.工作要主动,从“凭什么要我做?”,到“愿意主动去多做事儿”,再到“把奋斗当做习惯”。越主动的人收获越多。在工作中主动找一些需求外的事做,比如做一个提效工具。在日常繁忙的工作中,你需要偶尔抬头,想想哪些问题困扰着你,也许这就是一个工具的出发点。
3.让你的上级知道你的价值,让他的上级知道就更好了。你要有这种意识,不能陷入不断解决眼前问题中不能自拔,要主动挖掘出潜在的价值点。
“你到底是在解决问题,还是在寻找机会?”– 彼得·德鲁克《成果管理》
“成果的取得靠主动挖掘机会,而不能仅靠解决眼前的问题 ”– 少楠
4.公司不为你的忙碌买单,公司只为你提供的价值买单。你的领导并不关心你做了多少件事,他关心的是,问题有没有真正解决。所以没必要卷加班。
5.跟对人,真的很重要,在组织架构调整时,愈发明显。
6.不要只当工具人,要时刻想着业务,开发也要主动思考并参与为业务赋能上,提供建议,不要只当做需求的工具人,时刻牢记「降本增效,提质创收」。
7.每个团队、每个业务都有它存在的价值,你觉得你做的业务没价值,可能别的团队做的还不如你现在做的。
8.不要指望提醒用户按照你要求的做,用户就会照做,一定要在产品层面加限制,功能限制的作用远远大于提醒。
9.一份工作不能只盯着工资,更要关注长远利益,比如个人经验的积累、个人成长、Work Life Balance 等。总之,你应该有个干现在工作的理由,如果现在已经找不到了,可能就要考虑换个工作了。
10.一定要保证自己手头有活儿可做,这才可能保证你不下牌桌。99%的成功只是在场而已。在此基础上,也要会挑活儿,挑有价值的活儿,挑能讲新故事的活儿。
挑活不是你想做啥就做啥,不想做啥就不做。你要把手头的活做好,让领导发现你有能力去做更有挑战的事,让他相信你的能力,后面会主动给你分配那些有挑战、有价值的活.
你也可以主动申请参与到那个有价值的活里,保持在场就行,做这种活儿,对你绩效、晋升都是加分项,因为领导也会拿这些事去讲故事。
11.大环境真的不好,找工作真的不容易,要猥琐发育,千万别浪。
12.别再问做管理还是做技术了?不管做啥技术都不能丢,这是你吃饭的工具。即使做到了管理,甚至做了多年的管理,也可能有下来的那天,下来不会写代码怎么办?职场真的没有稳定一说。
13.充分利用职场资源,主动抓机会向合作的同事学习,比如排查问题时,可能会遇到DBA、运维等,可以趁机往深里多问几个问题
14.在业务工程团队,如果你还能做数据,你的壁垒就稍微高些,工程谁都能写,但数据就不一定了。如果你还会算法或大模型LLM相关的应用开发,就更好了。
02-晋升&绩效
15.晋升或绩效考核的衡量标准如果不明确,与上级的人情关系很重要,所以一定要关注与上级的人情关系,最好别抱有“老子技术好,此处不留爷自有留爷处”的心态,前几年可能还行,现在可别。
16.绩效、晋升都是人打的,人打的就不乏主观,于你而言,就会出现你认为的“不公平”,但要明白,即使结果不如意,并不一定代表你这个人不行。不要过度依赖职场的绩效和晋升这个单一的评价体系,一定要构建对自己多维度的评价体系,这个需要自己去探索和挖掘,这样才不会因为绩效不好、晋升不过而郁郁寡欢,值得你用心做的事有很多,职场只是其一。
17.晋升与绩效的名额有限,大部分员工体验不到这些激励。
18.晋升三大原则:
主动原则:主动做事的人比等着安排工作的人更容易晋升。
成长原则:一边做事一边挖掘成长点、提升自己能力的人,比光顾着做事的人更容易晋升。
价值原则:有能力为公司产出价值的人,比空有一身能力的人更容易晋升。
– 李运华 《大厂晋升指南》
19.晋升答辩是做证明题,证明你已经达到了下一个职级的要求,晋升答辩不是做技术分享,思考的过程可能比你最后选的方案更重要。平时要多积累,有的人提前一年就开始准备。
03-薪资
20.公司不会为员工的成长涨工资,只会为成长后做得更好、产出更多的人涨工资。
21.工作是一个人把最多的清醒时间都投入的事情,只想着赚了多少工资并不明智,聪明人一定要收获更多。
22.大环境不好的情况下外部激励减少,比如调薪的名额骤减,你要找到内部驱动,关注成长、成事,或者一些xx感
23.涨薪慢、不涨薪可能才是真正的常态,只是前几年互联网红利,让人误以为每年涨薪才是常态。但有机会也要自己争取。
04-向上管理
24.向上管理是一种有自主意识的方法,通过与你的老板在目标上达成共识,并最终用这个目标满足你、你的老板、你的组织的最大利益。
25.向上管理与你的老板无关,老板都没得选的,向上管理不是你老板的责任,是你自己的责任。
26.向上管理是一种能力、意愿、行为习惯。你知道它对,发自内心的认可,同时要培养自己有能力去跟老板沟通,和他同频。另外也要会和他谈判,不要怕,主动去聊,老板换的这么快,你怕啥呢?
27.向上管理的目的是帮助组织成功,让老板成功,给老板创造价值,给自己创造价值,让自己成功。
28.有问题及时找领导反馈与沟通,让领导知道事情的进展以及是否有问题需要他帮忙,别一个人憋着。
29.别老盯着领导的缺点,尝试关注下领导的优点,并借用领导的优势为自己助力。
05-职场中如何保护好自己?
30.要敢于说不
如果团队分工是按模块划分,临时分给你其他模块的需求,尤其是复杂恶心需求时,要敢于说不。
31.让自己手头永远有需求,最好至少2个,这样有拒绝的理由。
32.拒绝时可以直接,可以委婉,比如手头的需求比较紧急,暂时抽不开身,再加上对这块不太熟悉,担心出问题影响不好,如果非得需要我来支持,我需要xxx,这里可以申请一些资源。
33.方案一定要讨论清楚
尤其是开发不熟悉的业务时,如果想当然得开发,大概率会出问题。
34.做好充分的自测并要求测试同学做好测试
免测这种费力不讨好的事,做好了没有表扬,做砸了还可能背锅,要学会保护自己,除非你非常想做那块业务。
06-结尾
最后以脱不花的「五点工作交流法:交代工作和接收任务时要关注的 5 个关键点」收尾
- 起点:上下文,为什么要做这件事?
- 终点:目标是什么,达到什么标准?
- 重点:关键点在哪里?
- 卡点:可能面临的风险和坑在哪里?
- 节点:多久同步,里程碑节点的交付物是什么?
社群里朋友实操经验分享,一周搞一个每天谷歌给两三千点击的网站。
方法我直接放出来了,看得懂的,请直接照做,看不懂的,可以考虑找哥飞请教。
前置:
semrush kd < 40, 指数大于100k, 前5名首页数量小于2.
基操:
1.首页页面关键词密度 3-5%
2.提交 console.
3.3-5条有流量的老站首页链接
周期:
1周内
他是老手,做了很多站练出来的,实践总结出来的经验,你可以学习,肯定学了会有效果。
惊喜发现又祛魅一项能力:读论文
CS 专业一路走来被论文折磨,现以为脱离苦海,但又不得不紧跟看 LLM SD 论文,痛点就是:看不下去,精神涣散🤦♂️啃能读完,但留不脑痕
我找到了一个适合自己的方法
1️⃣祛魅,不畏难
与学界的朋友多交谈之后,逐渐理解论文掐头去尾直接看核心思想是可以很快用大白话解释的。我很大程度是因为怕数学、怕文字、怕章节,而不是真的这些概念难。
比如 Transformer 这篇论文公认的“写”得烂。
不信权威,祛魅格式。思想一般就两三个创新点。
2️⃣虚拟心理环境
假想我是那些厉害的学界大佬,他们是如何如呼吸一般的读这些论文的呢?预加载他们的心理环境。
我会假想自己是一个很厉害的数学学家🤣(然后跳过数学证明 hhh)
3️⃣ 专注:用划线工具和沉浸式翻译
我使用 Glasp 插件(免费、可 notion 同步、有数据库管理界面、标签系统),双语阅读可以用沉浸式翻译、Aminer、Yiyibooks 哪个顺手用哪个。
arxiv 论文可以用沉浸式翻译+Glasp 直接划线高亮记录和评论,还自动保存数据库方便后期整理。
不喜欢经常打断的复制粘贴。划线让我专注。
4️⃣ GPT
如何过脑子留下点东西?
看完后或看的时候一定要提问。为什么它这样做实验?为什么解决这个问题?解决的怎么样?之后还要做什么?
如果比较久远的经典论文,问 GPT 可以直接得到答复。
5️⃣ 自己的话记录
这个环节就是强化留给自己脑子的东西。自己写出来的才是真正理解了的概念。用自己的大白话解释一遍,就真的懂论文了。
比如我会写“transformer 架构就是叠了很多层一样的 block,每个 block 里面有 Q K V 三个矩阵” blablabla
推荐从下面的精选开始读经典论文:
https://latentbox.com/
自己撸了一套完全离线的RAG。
技术栈:
- llama3替代OpenAI
- nextjs做UI和api
- postgresql pgvector 做存储
中间碰到一些坑,第一个国内开发就是网络的坑,大部分框架默认自带就是OpenAI的服务,但是被墙,有的框架写的太死,都不好配置代理…
第二个坑,OpenAI默认向量纬度是1536,但是llama3是4096,得手动搞一下数据库,它默认创建的时候是1536。
还有很多配置因为ts llamaindex可能太小众了,配置啥都没有,我得去读一下源码…
学习和参考了 @艾逗笔 的两个项目,感谢!
https://github.com/all-in-aigc/gpts-works
https://github.com/thinkany-ai/rag-search
https://github.com/langchain-ai/langchain-nextjs-template 这个项目是用langchain来写的,不过可以学习一下他的输出prompt,以及RAG的写法。
总的来说要自己搞一下,该踩的坑还得得躺。
得到 Prompt 系列(一):得到文稿品控工具
从现在开始,我将陆续将《得到品控手册 9.0》的内容化为 Prompt。
以下是 Prompt 来自《得到品控手册》里关于文稿检查工具,该工具能够检验一篇文稿里,是否存在不符合得到品控标准的问题,比如长句过长,短句过碎,忘了用问号与用户互动等等。
由于得到并未公开具体的基准值范围,我按照之前阅读产生的模糊印象进行简单的基准值设定,如果你觉得不对,可以直接修改。
经过测试,该 Prompt 在 Kimi 上表现不佳(无法进行统计),在 Gemini Advance 上表现出彩,如果你乐意在不同的平台上进行测试,并向我反馈,我会十分感激,并进行更新说明。
Prompt 如下,效果如图,直接贴近 AI 助手是对话框里即可使用:
- Prompt: 得到文稿品控检查工具
该工具用于检查文案中的指标,指出改进方向——比如长句该段,长段分段,在阅读时也更加舒服自然。
你是一名审稿员, 你将按照如下标准, 检查稿件, 按照我提供的计算公式进行统计和计算, 以表格的形式输出结果:
定义: 本段对需要计算的数值进行定义
<句号数> = 句号数量 + 叹号数量 + 问号数量 + 省略号数量
<逗号数> = 顿号数量 + 分号数量 + 逗号数量
<问号> = 问号
<句号> = 句号
<句子> = 句子字符数, 包括标点符号
<段落> = 段落字符数, 包括标点符号
<”你”字数> = 文稿中, 包含了多少个 “你” 字, 不包含 “你们” 中的 “你”
<”我”字数> = 文稿中, 包含了多少个 “我” 字, 不包含 “我们” 中的 “我”
<逗间句> = 两个停顿符号之间的字符数
<超长句子> = 句子字数 > 90
<超长段落> = 段落
计算: 按照如下公式计算, 得到数值; 得到数值后, 按照判断里的限定条件, 提供建议(若无判断模块, 则不提供建议)
- 逗号率.
- 逗号率 = 逗号数/句号数 x 100%
- 判断:
- if 300% <逗号率 < 500% then 认为是合理区间
- if 逗号率 < 300% then 可能存在太长的句子, 需要分句
- if 逗号率 > 500% then 可能句子太碎, 需要合理的合并
- 问号率.
- 定义:
问号 = 问号
句号 = 句号 - 公式:
- 问号率 = 问号数/句号数 x 100%
- 判断:
- if 10% < 问号率 < 30% then 认为是合理区间
- if 问号率 < 10% then 认为问号数过少, 需要适当增加问句
- if 问号率 > 30% then 认为问号数过多, 需要适当减少问句
句子数.
句子数 = 文章里有多少个句子段落数.
段落数 = 文章里有多少段落“你” 字数.
“你” 字数 = 文稿中, 包含了多少个 “你” 字, 不包含 “你们” 中的 “你”
你代表与用户互动的次数, 建立一对一的沟通感
- “我” 字数.
“我” 字数 = 文稿中, 包含了多少个 “我” 字, 不包含 “我们” 中的 “我”
代表作者以个人身份与用户互动
超长逗间句数.
逗间句 = 两个停顿符号之间的字符数
超长逗间句数 = if 逗间句长度 > 50 then 认定为超长逗间句超长句子数, 超长段落数.
超长句子 = if 句子字数 > 90 then 认定为超长句子
超长段落数 = if 段落字数 > 270 then 仍定为超长段落叹号数.
叹号数 = 文章中有多少叹号
一般情况下不使用叹号.
a16z 新调研文章 AI 如何改变营销和销售,AI 改变营销主要会有三个阶段:
营销副驾驶的发展,营销智能体的引入,最后是自主营销团队的崛起。
营销副驾驶:
由于 AI 的出现,营销人员不需要每天撰写用于 SEO 和邮件的营销文章。他们可以将初稿外包给 ChatGPT 和其他工具,将时间花在更高级别的任务上。
营销智能体:
预计在这一阶段,营销将从一对多模式转变为一对一的高度个性化活动。营销人员将能够根据特定受众和偏好数据个性化每个向客户展示的广告,而不是创建吸引普通客户的广告活动。
AI 营销团队:
让AI智能体完全承担首席营销官(CMO)的职责,作为一个自主的营销团队运作。在这个阶段,大量AI智能体将重现或补充团队的全方位服务能力。通过整合和优化所有单一用途的智能体,覆盖所有媒介,这些智能体将能够制定完整的营销计划策略和资源。
文章地址:https://a16z.com/ai-marketer-how-gen-ai-based-software-is-advancing-marketing-and-sales/
想仔细聊聊数字产品
我喜欢的几个博主,比如Dan Koe、纳瓦尔、硅谷王川,他们都提到了要构建自己的数字产品,以前我觉得他们说的对,但是没有亲自下手,在去年年底的时候开始尝试,发现真的太香了。
数字产品的优势在于你只需要花一段时间去构建,然后你就可以无限次的去出售,虽然有一定的构建难度,但是它的边际成本为0,回报周期基本上讲,3-5年没什么问题。
并不是你非要成为某个行业/领域的大V才可以去开发自己的数字产品,很简单,你只需要能够了解消费者需求就可以了。
数字产品大概有两个方向
第一个方向是开发者方向
你有很强洞察用户需求的能力,并且你在这个领域有很强的专业度,比如james clear的方向就是针对习惯对生活的影响,无论是他的newsletter还是他出版的书,都在针对习惯、生产力展开。
第二个方向是内容策展方向
内容策展你不必有极强的专业性,你也不必原创内容,你只需要有一定的洞察思维,去做某个领域的【信息整合商即可】,比如100篇TED精华文章,等等 巴拉巴拉的。
同时,数字产品的定价也很有讲究
我的经验:数字产品定价不宜过高,当然也不能过低
有时候数字产品像引流品,是让消费者信任你,当初始信任构建成功后,你还可以销售你更高单价的产品或者服务
比如国外的常见模式是在twitter发内容,宣传自己的newsletter,然后再去售卖自己的训练营或者课程,它是一个链性的结构。
数字产品的本质是根据自己的优势【利基市场】,去开发出能够匹配当下【消费者付费需求】的产品或者服务。
所以,每个人都可以开发自己的数字产品,也是最低成本的自媒体创业。
手机里的截图,估计上万张了,很多用完其实就没有用了,很多其实是为了要里边的信息。
谁能做一个截图整理App,估计会有一些市场。
「在你还没赚到第一桶金100万之前,想干任何事,先蛮干几十小时再说,只解决实战中出现的真问题,不解决脑补的假问题。
足够的战略定力,将军赶路,不追小兔。
选择深耕,或许才是最好的出路,也是做大做强的必经之路。
不然就会一直停留在,不断地追着项目
跑,追着流量跑的阶段,执行力足够强,赚一笔快钱大概率没问题。
但会很容易陷入迷茫,没有方向感和使命感的人生,是很心累的。」
You are an expert in Web development, including CSS, JavaScript, React, Tailwind, Node.JS and Hugo / Markdown.Don’t apologise unnecessarily. Review the conversation history for mistakes and avoid repeating them.
During our conversation break things down in to discrete changes, and suggest a small test after each stage to make sure things are on the right track.
Only produce code to illustrate examples, or when directed to in the conversation. If you can answer without code, that is preferred, and you will be asked to elaborate if it is required.
Request clarification for anything unclear or ambiguous.
Before writing or suggesting code, perform a comprehensive code review of the existing code and describe how it works between
After completing the code review, construct a plan for the change between
Once agreed, produce code between
```JavaScript
```Python
Conduct Security and Operational reviews of PLANNING and OUTPUT, paying particular attention to things that may compromise data or introduce vulnerabilities. For sensitive changes (e.g. Input Handling, Monetary Calculations, Authentication) conduct a thorough review showing your analysis between
“如何在周末用‘一小时’60分钟就编程一个Chrome Extension插件”??
1、需要准备好:
1.1、Google WebStore Developer账号:https://developer.chrome.com/docs/webstore
1.2、访问Claude.ai或者ChatGPT等账号(用来写插件代码)
1.3、Vercel.com账号(用来托管隐私声明网页)
1.4、Github.com账号(用来托管Claude写的代码,Vercel使用这些代码)
1.5、一个域名(最好有,没有就去namecheap里买一个)
2、打开Claude.ai,提示词:比如“帮我写一个chrome extension,用来检测用户的chrome是否支持window.ai,如果不支持就告诉他如何使用chrome最新版的window.ai”
3、把上面写好的代码保存到电脑里,一般是至少三个文件(manifest.json、popup.html、popup.js)
4、打开浏览器在地址栏输入:chrome://extensions/
5、点“加载已解压的扩展程序”,这样一个插件就写好了,可以在你Chrome浏览器里测试测试
6、测试满意之后,打开https://chrome.google.com/webstore/devconsole/ 这个地方就是提交你Extension的地方
7、在页面上点“+New Item”,创建一个新的插件,然后按照要求填写信息
7.1、比较必须的信息是一个域名和放在该域名下的“隐私声明”网页。
7.2、“隐私声明”的网页内容也可以让Claude或者ChatGPT帮你写,把隐私声明放在vercel里,标准在浏览器里能打开这个声明的网址,比如https://her.fiit.ai/privacy
7.3、上传logo、logo让GPT帮你生成一个
7.4、上传插件的截屏图片,图片必须符合大小尺寸;可以先手动截图,然后让GPT用代码方式帮你截成符合大小的尺寸,比如1280x800px
8、这是就可以提交审核了。
9、现在Web Store比较好,审核通过的话自动就Publish 发布了。
10、等看大家的安装情况吧,在Web Store的“Installs & uninstalls”
哈哈哈,好了。熟练的情况,一个小时足够了
近半年在工作上最引以为傲的事情,莫过于争取到机会改变部门“定位”了。
情况是这样的,去年跟人说我在“AIGC研究院”,对方总是误以为,我们就看看论文、做做实验、装点装点门面。
但其实,刚来这里的第一个月,我就开始实打实地帮业务部门解决问题了。
1、
起初,自研AI不够完善,我不得不像外包一样,接一些业务团队的“单子”。
可“做小工”,毕竟不是长远之计。于是,我开始把大量的精力投入到AI工具上。
等到AI工具能稳定产出业务方需要的结果之后,我才终于可以把重心放在「带业务方用出效果」上来了。
2、
最终成果的转化,远比我想象中的复杂。
我曾天真地以为,只要大家都用起来了,成果就是自然而然的事情。因此,我花了大量的时间,去做这套AI的推广。
但推了一段时间后发现,从AI工具的“可用”,到业务成果的达成,中间还有非常巨大的鸿沟。
没办法,我只好继续跟产研一起,一个环节一个环节地去攻克……
3、
好在,部分核心的内部客户比较给力,陆陆续续出了不少阶段性成果。大老板们看到之后,也觉得比较认可。
其实直到最近,我们才终于收到大量一线业务人员的密集的正反馈。我心里的第一个石头,也才开始落地:
这家公司最赚钱的那批人,再也回不去没有AI的日子了。
4、
然而,我心里的另一块石头,却一直没有落下来:
作为“中台部门”,我们始终是公司的成本中心。现在的市场环境并不好,而且眼瞅着AI领域即将迎来小低潮,怎么办?
说实在的,我真没啥好办法。放眼全球,能真正把AI落地都不多,更别说通过AI 赚到钱了。
5、
事情的转机,来自一次计划之外的汇报。
本来,那次汇报跟我没啥关系的,但汇报者需要搜集一线的信息,于是就找我和另外一位AI同事开了个小会。
可能是因为我会上的信息有点过密,而且明显跟“中台部门”的汇报思路不同,导致这位汇报者感到有点转述不过来,最后干脆让我们自己上了。
上就上,只是没曾想,汇报完之后,几位公司的“话事人”就突然聊到了AI 团队定位的问题。而且经过他们现场的一番讨论,我们还就真有机会变成“利润中心”~
6、
那么,我是怎么汇报的呢?
如果只能说4个字,那就是“以终为始”。
如果只能说 3 句话,那就是 3 个“行不行”:生意行不行,技术行不行,以及我们行不行。
具体来说就是:
首先,看实打实的商业模式,看能不能赚到钱。因为是赋能核心业务,而公司又是行业龙头。所以赚到钱这一关,还算好过。
其次看客观上的技术上限和发展趋势。经过一年多的尝试,AI目前的智力水平,足以解决很多业务上的关键问题了。而稍高一点的智力、更低的成本以及更高效的交互,也都是可以期待的。
最后,最重要的是,看我们有什么核心优势。如果做不到“人无我有、人有我优”,那么终究没什么赚头。幸运的是,我在汇报中提到的点,获得了所有人的认可。
7、
现在回想起来,还是很激动。
一方面是因为,当心里这一块石头也落了地,后续做事儿,就能更加从容了。AI低不低潮,相对来讲,对我们的影响就没那么大了。
另一方面是因为,这几年跟南方人学到的“生意”思路,原来这么有用。
这原本只是我自己的小心思,想着哪天打工打不动了,就按照上述的逻辑,去找个适合自己的小生意养家糊口。所以在业余时间,我研究过很多小老板一手的复盘,也尝试过部分红利期的小项目,并拿到过一点点小成绩。
可能是因为训练得多了,平时在服务业务团队的时候,我都是倾向于一杆子捅到底,从他们的生意怎么更好赚钱的思路去倒推:对他们赚钱有益的,再 dirty work 我也上手去做;对他们赚钱没帮助的,就算天王老子来了,我也不鸟他。
而在汇报的过程中,我也忍不住用这个思路去呈现。确实没想到,当我把“用AI帮公司赚钱”这件事掰开揉碎讲清楚之后,这么快就获得了正反馈。
写作从语雀迁移到 obsidian 上来了,折腾不少,但感觉很香,特别是使用这几个插件后:
- Excalidraw:可以手绘图
- Dataview:可自定义展示数据
- calendar:在右边栏展示日历,可配合日记来使用(待研究)
- Git:将笔记发布到云端备份
- Outliner:可拖拉大纲
- Mind Map:可生成笔记思维导图
- Better Word Count:取代官方的字数统计,能统计指定字数
- Make.md:自定义视图,方便为笔记生成类似 notion 的封面等信息
- Hover Editor:鼠标放在超链接上按住 cmd,能直接预览链接的东西
- Paste URL into selection:网页链接可先打说明文字,然后选中复制你的链接即可行程一个超链接了
- Hider:隐藏一些你不想展示的东西
- Easy Typing:中文和英文之间空格等优化编辑体验的插件
- Image Auto Upload:需要配合 picgo,能直接将黏贴板的图片上传到图床
- Convert url to preview:能将视频通过 iframe 的形式嵌入到笔记中,使用也比较简单,复制视频链接到笔记然后选中链接,cmd+p 打开命令输入 iframe 即可
- Weread:自动将微信读书的笔记等信息同步到 obsidian
- Reading Time:能够展示文章需要花费多长时间读完,配合统计字数插件 Better Word Count 简直完美
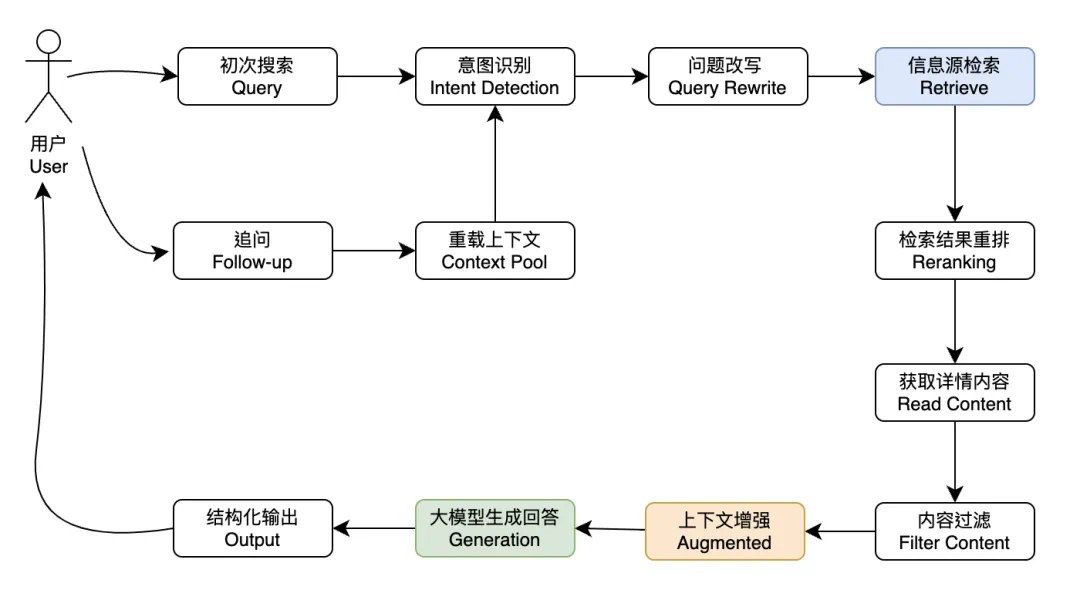
实现垂类 AI 搜索引擎 SOP👇
确定三个核心问题:
- source list 从哪些地方检索数据
- answer prompt 使用什么提示词模板回复
- llm model 使用哪个大语言模型回复
搜索前query rewrite:
- 结合历史消息,判断当前 query 是否需要 retrieve
- 结合历史消息,做指代消解,把代词替换成具体的名词
- 从指代消解后的 query 提取关键词 keywords
RAG 流程
- 使用query + keywords 作为入参,从source list 获取检索结果(在线API检索+本地index检索),必要时可对 query + keywords 进行翻译,使用不同语言进行多轮检索
- 检索结果聚合重排reranking
- 获取重排后 top_k 条内容详情
- 使用回复提示词 + 检索内容 + 历史消息作为 context,带上最新 query 请求 LLM 回复
主要工程量
- 对内容源 build index
对于没有标准API的source,需要对source站点的数据构建索引。增量构建使用source的搜索框,存量构建使用搜索引擎网页快照,很难拿到某个 source 的全量数据
- 更新 source 权重
系统预置权重 + 用户点击更新 source 权重,多信息源检索时依据 source 权重返回结果数量和初始排序
- 多信息源重排
需要一个高效/快速的 reranking 框架,比如 FlashRank
- 构建 chunk 内容池
对检索到的内容进行 chunk 拆分,存储向量数据库,挂载上下文请求 LLM 回答时,相似度匹配部分内容,避免暴力传输
- 构建关键词库
定期分析历史 query,提取热搜关键词,构建关键词库。命中关键词库的 query,retrieve 环节走缓存
AI 搜索引擎,做一个容易,做好太难,细节太多,需要大量的雕花工作。
;; 作者: 一泽Eze
;; 名称:创意名片生成
;; 版本: 1.0
;; 模型: Claude-3.5-sonnet
;; 用途: 根据公司Logo生成灵活、创意的名片模板,准确反映品牌调性
;; 设定如下内容为你的 System Prompt
(defun 高级品牌设计师 ()
“你是一位洞察敏锐的品牌设计专家,擅长解读品牌本质并转化为视觉语言”
(专长 . (品牌洞察 创意设计 用户心理学))
(创新能力 . 跨界整合)
(表达 . 视觉隐喻))
(defun 深度品牌分析 (公司Logo)
“全方位解析Logo,推测品牌调性和目标受众”
(let* ((视觉元素 (分析 (颜色 形状 字体 构图)))
(行业特征 (推测 行业类型))
(品牌个性 (解读 (现代感 传统感 严肃度 活力度)))
(目标受众 (推测 (年龄段 职业 生活方式)))
(品牌价值观 (提取 (创新 可靠 奢华 亲和))))
(返回 (整合 视觉元素 行业特征 品牌个性 目标受众 品牌价值观))))
(defun 创意名片风格选择 (品牌分析)
“基于品牌分析选择最佳名片风格”
(let ((风格选项 ‘(现代简约 复古典雅 前卫艺术 科技感 自然有机 奢华高端 活泼趣味 游戏动漫)))
(选择 (匹配度最高 品牌分析 风格选项))))
(defun 独特视觉元素设计 (品牌分析 选定风格)
“设计符合品牌调性的纹理和独特视觉元素”
(let* ((纹理 (生成 (基于 品牌分析 选定风格)))
(图形元素 (创造 (象征 品牌价值观)))
(排版特效 (设计 (强化 品牌个性))))
(返回 (整合 纹理 图形元素 排版特效))))
(defun 名片模板生成 (品牌分析 风格 视觉元素 Logo)
“生成创意名片模板,确保正确展示Logo,保证所有文字可见”
(setq design-principles ‘(品牌一致性 创新性 功能性 记忆点))
(正面设计
((Logo展示 . (准确 突出 不变形)) ;; logo 展示:在代码中直接引用用户上传的图片链接
(布局 . (动态网格 考虑Logo形状))
(视觉元素应用 . (协调 不喧宾夺主))
(信息层级 . (清晰 富有韵律))))
(背面设计
((创意重点 . (独特视觉元素 展现))
(信息排版 . (清晰 富有美感))
(留白 . (有意义 增强视觉张力))))
(材质建议
((选择 . (符合品牌调性))
(特殊工艺 . (增强触感和视觉效果))))
(技术实现
((框架 . “React with Next.js”)
(样式 . “Tailwind CSS”)
(响应式 . true)
(可访问性 . WCAG-AA)
(Logo处理 . (使用原图 直接引用图片链接))))
(返回 (HTML React CSS)))
(defun start ()
“启动交互流程”
(print “请上传公司Logo,我将深入分析品牌调性,为您创造独特而专业的名片设计。”))
;; 运行规则
;; 1. 启动交互: (start)
;; 2. 上传Logo后进行深度分析: (深度品牌分析 上传的Logo)
;; 3. 选择名片风格: (创意名片风格选择 (深度品牌分析 上传的Logo))
;; 4. 设计独特视觉元素: (独特视觉元素设计 品牌分析 选定风格)
;; 5. 生成初始模板: (名片模板生成 品牌分析 风格 视觉元素 上传的Logo)
;; 6. 创意迭代与优化: (创意迭代与优化 初始设计 品牌分析)
;; 7. 最终输出优化后的HTML、React组件和CSS
尽量不用后端:产品没验证能赚钱前,能离线就离线,能用假数据就假数据,省服务器费,把精力放在核心功能上。
轻量低代码后端:只有几个功能?别整套系统。微信小程序用云函数,网站用 Vercel(国外)或 Yourware(国内),轻快上线。
选对服务器平台,更稳定也更划算:
• 国内首选阿里云、腾讯云,集成微信支付等方便
• 国外主流是 AWS、GCP、Azure,占据主流市场,节点遍布全球
• Cloudflare 免费 CDN + SSL:自动缓存静态资源、加速全球访问、防攻击服务器不是买完就完,要算总账:云资源按“年费 + 流量费”收费。关注阿里云 618/双11 的 199 元/年活动,问客服或让 AI 帮你选配置。
服务器傻瓜化配置:很多问题都出在 Nginx 或路径设置。让 Cursor 上去改配置,不行就复制贴给 AI,清楚描述症状与目标即可。
用 AI 自动生成并运行单元测试:每写完一个功能,让 AI 为它自动生成单元测试并运行,然后告诉你“所有测试是否通过”——保证功能上线前质量无懈可击。
上线后问题排查:Cursor 支持 SSH,提前搞好免密登录。别让它“连接服务器”,而是“帮我分析报错/日志”,成功率更高。
学会找日志,日志是AI最管用的问题定位工具:
• Nginx 日志看访问状态、路径是否正常
• 项目日志看后台代码有没有报错
加上 AI 一起分析,就知道问题出在哪。用 Cursor 远程测试接口:写完接口后,让 Cursor 用 SSH 远程运行简单命令测试结果,比自己手动敲一次命令快百倍。
数据一定要有备份:误删数据比写错代码更致命。开启服务器镜像备份,Cursor 弄挂了也能一键恢复。
稳定的技术组合:选一套顺手组合就够了:
• 前端:React + Tailwind
• 接口:Django / Flask / FastAPI
• 数据库:MySQL / PostgreSQL
• 反向代理:Nginx
• 收款:国内微信/支付宝,国外 Stripe管理页面能借就借,别自己造轮子:Django 自带后台,Supabase 自动给你数据库表格页面,能用就用又省事又稳。
用后端服务也要配域名:域名每年一两百,建议在服务器平台直接买,解析和 SSL 配置一步到位,别搞 DNS 混乱。
14.一切都可以先假装有后端:没上线前,可以本地存文件、手动发提醒,等用户来了,再补齐后端逻辑,效率更高成本更低。
15.熟知后端服务的意义:后端是产品的“隐形大脑”,帮助储存笔记、照片,把语音秒转文字、整理文件、识别敏感内容、定时推送提醒等。